4 比較演算
今回は比較演算子の使い方を学びます。 比較演算ができるようになれば,条件分岐と繰り返し処理の理解が進みます。
4.1 比較演算
比較演算とは比較演算子を使った判定のことです。 数値の比較はみなさんが日常的に行ってことですので,分かりやすいはずです。
4.1.1 数値
比較演算子の1つに == があります。
## [1] TRUE## [1] FALSE= は必ず2つ連続で使用します。
= を1つしか使わない場合,関数の引数以外では,<- と同じ意味になってしまいますので,注意が必要です。
上のコマンドは,== の左側と右側が等しいかどうかを判定しています。
比較演算の返り値は論理値です。
また,ベクトルを比較演算子の左側に置いた場合,返り値は左側のベクトルと同じ長さのベクトルになります。
## [1] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE TRUE FALSE
## [13] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE## [1] 21## [1] 11ベクトルの各要素を表示し,返り値との対応関係が正しいことを確かめてください。
## [1] 1990 1991 1992 1993 1994 1995 1996 1997 1998 1999 2000 2001 2002 2003 2004
## [16] 2005 2006 2007 2008 2009 2010Rコンソールに表示されるベクトルが何行目で改行されるかは,そのベクトルによって異なります。
このため,2行目がベクトルの何番目であるかはそのベクトルに依存します。
左の [] 内に表示される数字がベクトルの何番目の要素であるかを示しています。
== のほかに,次のような比較演算子があります。
これらの比較演算は直感的に理解できるはずです。
## [1] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE TRUE
## [13] TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUEここで,ベクトルの各要素1つずつに対して比較していることを理解してください。
現在,year は次のようになっています。
## [1] 1990 1991 1992 1993 1994 1995 1996 1997 1998 1999 2000 2001 2002 2003 2004
## [16] 2005 2006 2007 2008 2009 2010このベクトルの1つ目の要素と 2000 を比較した結果が year > 2000 の返り値のベクトルの1つ目の要素 FALSE に対応しています。
そして,このベクトルの12個目の要素と 2000 を比較した結果が year > 2000 の返り値のベクトルは12個目の要素 TRUE に対応しています。
以下の比較演算子についても同様です。
## [1] TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE FALSE FALSE
## [13] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE## [1] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE TRUE TRUE
## [13] TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE## [1] TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE FALSE
## [13] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE>= は => とするとエラーが返ってきます。
<= も同様に <= としてはいけません。
ここでもベクトルの返り値がベクトルであることに注意してください。
比較演算子の先頭に ! をつけることができます。
この ! は否定を意味します。
== の場合は,!= とすると == が真ではないものという意味になります。
## [1] TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE FALSE TRUE
## [13] TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE!= の返り値は, == のちょうど反対であることが分かるはずです。
なお,!> や !< は使えません。
> の否定は <= で表現できるため,これらのコマンドが使えなくてもとくに困りません。
比較演算は,ベクトルや行列の一部を取り出すときによく使います。 例えば,次のようにします。
## [1] 2000 2001 2002 2003 2004 2005 2006 2007 2008 2009 2010一見冗長な書き方のように見えますが,これで問題ありません。
[] の内側は論理値のベクトルであり,[] の外側( year )のベクトルと長さが同じ(または,外側が内側の整数倍)でなければなりません。
この場合は [] の外側と内側で同じ変数 year を使っているので,必ずベクトルの長さが同じになります。
[] の外側のベクトルに対して,内側のベクトルの長さが短い場合は,内側のベクトルを繰り返します。
例えば,次のようにすると,c(TRUE, FALSE, FALSE) は7回繰り返され,返り値は7つの要素を持つベクトルになります。
## [1] 1990 1993 1996 1999 2002 2005 2008length(year) が 21 であり,これを length(c(TRUE, FALSE, FALSE)) の 3 で割ると,7 になります。
[] の外側が内側の整数倍の長さのベクトルという性質を使うことはほとんどないため,このことを知らなくても困ることはほとんどないでしょう。
むしろ,ベクトルの長さが違っていてもエラーにならない可能性があることから,思わぬバグに気づかないかもしれません。
比較演算は,実際によく使います。 例えば,次のような使い方をします。
year <- 1990:2010
y <- seq(5000, 5040, 2)
z <- data.frame(year = year, value = y)
mean(z[z$year > 2000, ]$value)## [1] 5031最後の部分は次のようにしても同じです。
## [1] 5031このことがいまいちピンとこない人は,次のように分解して考えてみてください。
## [1] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE TRUE
## [13] TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE## year value
## 12 2001 5022
## 13 2002 5024
## 14 2003 5026
## 15 2004 5028
## 16 2005 5030
## 17 2006 5032
## 18 2007 5034
## 19 2008 5036
## 20 2009 5038
## 21 2010 5040## [1] 5022 5024 5026 5028 5030 5032 5034 5036 5038 5040## [1] 5031これまでの説明で,返り値が論理値であることが混乱を招く原因になっているかもしれません。
しかし,これは R の便利な特徴のひとつですので,必ず理解してください。
もしかしたら,判定が真となる要素がベクトルの何番目の要素であるかを返す関数 which() の方が理解が容易でしょうか。
## [1] 11 12 13 14 15 16 17 18 19 20 21このため,次のようにすることができます。
## [1] 11 12 13 14 15 16 17 18 19 20 21## [1] 5020 5022 5024 5026 5028 5030 5032 5034 5036 5038 5040ただし,これは次のようにすることと同じです。
## [1] 5020 5022 5024 5026 5028 5030 5032 5034 5036 5038 5040返り値と関数の引数は異なります。 このように,ベクトルを取り出すとき,何番目であるかを指定する方法と,論理値で指定する方法の2つがあることを知っておいてください。 今後自分でコードを書くとき,このことが混乱の原因になるかもしれません。 もし混乱した場合は,そのとき扱っている変数が数値なのか論理値なのかを考えると,頭の中が整理されるはずです。
4.1.1.1 NA
ベクトルに NA が含まれるとき,NA のある場所では評価(比較演算)しません。
## [1] FALSE FALSE TRUE TRUE FALSE TRUE TRUE TRUE FALSE NA## [1] 10 9 6 7 8 NANA を取り除きたい場合は,条件をもう1つ追加しなければなりません。
NA かどうかは次の関数で判定します。
## [1] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE TRUE実践では,NA 以外を取り出したい場合は,否定の ! が使えます。
## [1] TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE FALSENA を取り除くと,ベクトルの要素の数が減ることに注意してください。
## [1] 9## [1] 10このベクトルがデータフレームから取り出したものである場合,そのデータフレームに NA を取り除いたベクトルを戻すことはできません。
行の対応関係が崩れるため当然ですが,勘違いしやすいので注意してください。
NA が含まれる計算結果は NA となるため,NA を取り除きたくなるかもしれません。
## [1] NAこの場合,関数の引数に na.rm = TRUE を入れて,一時的に NA を取り除いて計算してください。
## [1] 54この場合,x[!is.na(x)] のように,ベクトルからわざわざ NA を取り除く必要はありません。
判定の際に NA を取り除きたい場合は,次のようにします。
## [1] 10 9 6 7 84.1.1.2 論理積
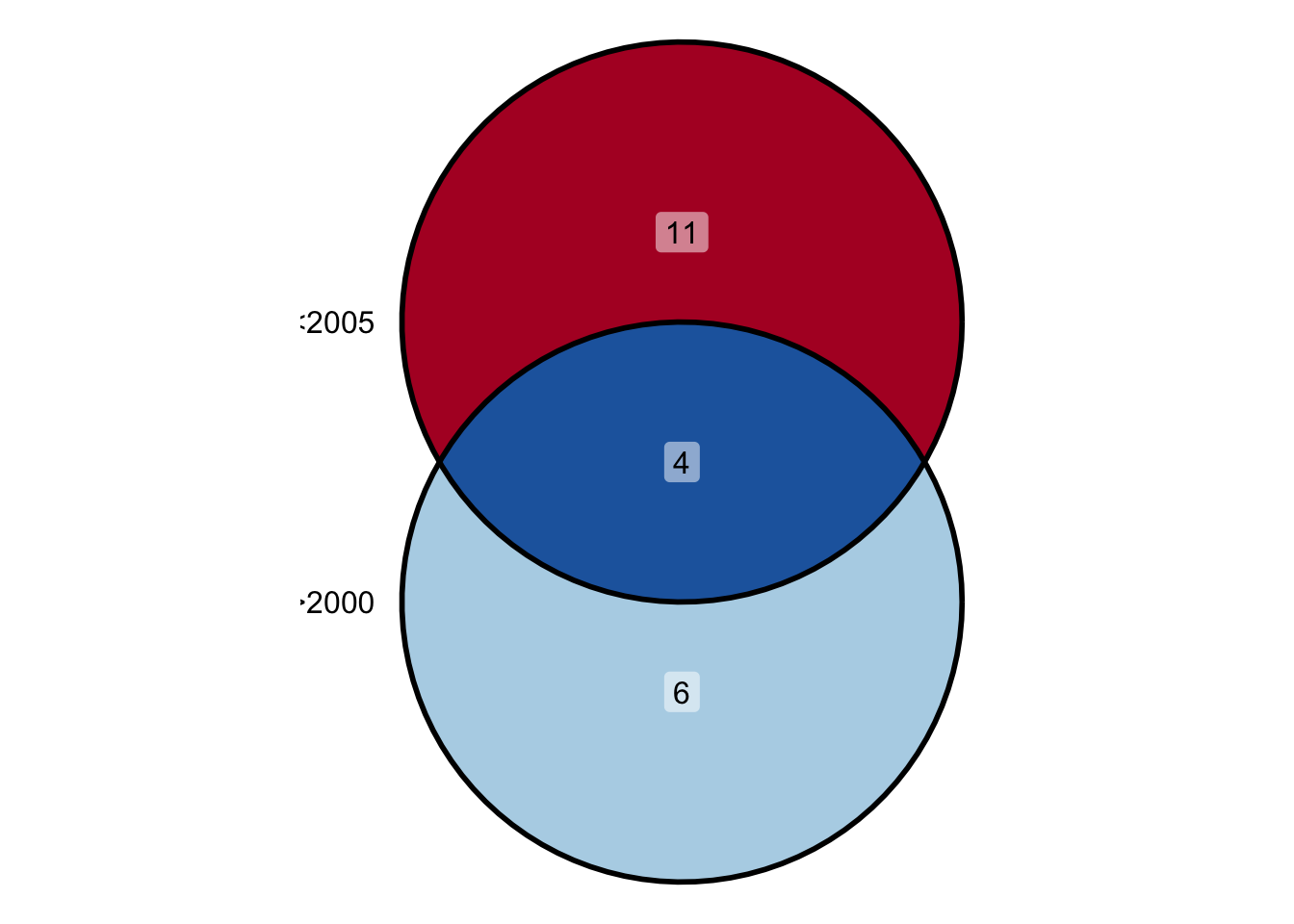
& は論理積と呼ばれるもので,英語の”and”,日本語の「かつ」という意味を持ち,判定の条件を増やすことを意味します。
NA に限らず,複数の比較演算を使いたい場合は,論理積 & を使います。
もっと単純な例としては,以下のようなものがあります。
## [1] 2001 2002 2003 2004論理積は以下のベン図で表現できます。
4.1.1.3 論理和
複数の比較演算のいずれかが真となるという条件式を書きたい場合は,論理和 | を使います。
例えば,次のようにします。
## [1] 1990 1991 1992 1993 1994 2006 2007 2008 2009 2010論理和は以下のベン図で表現できます。
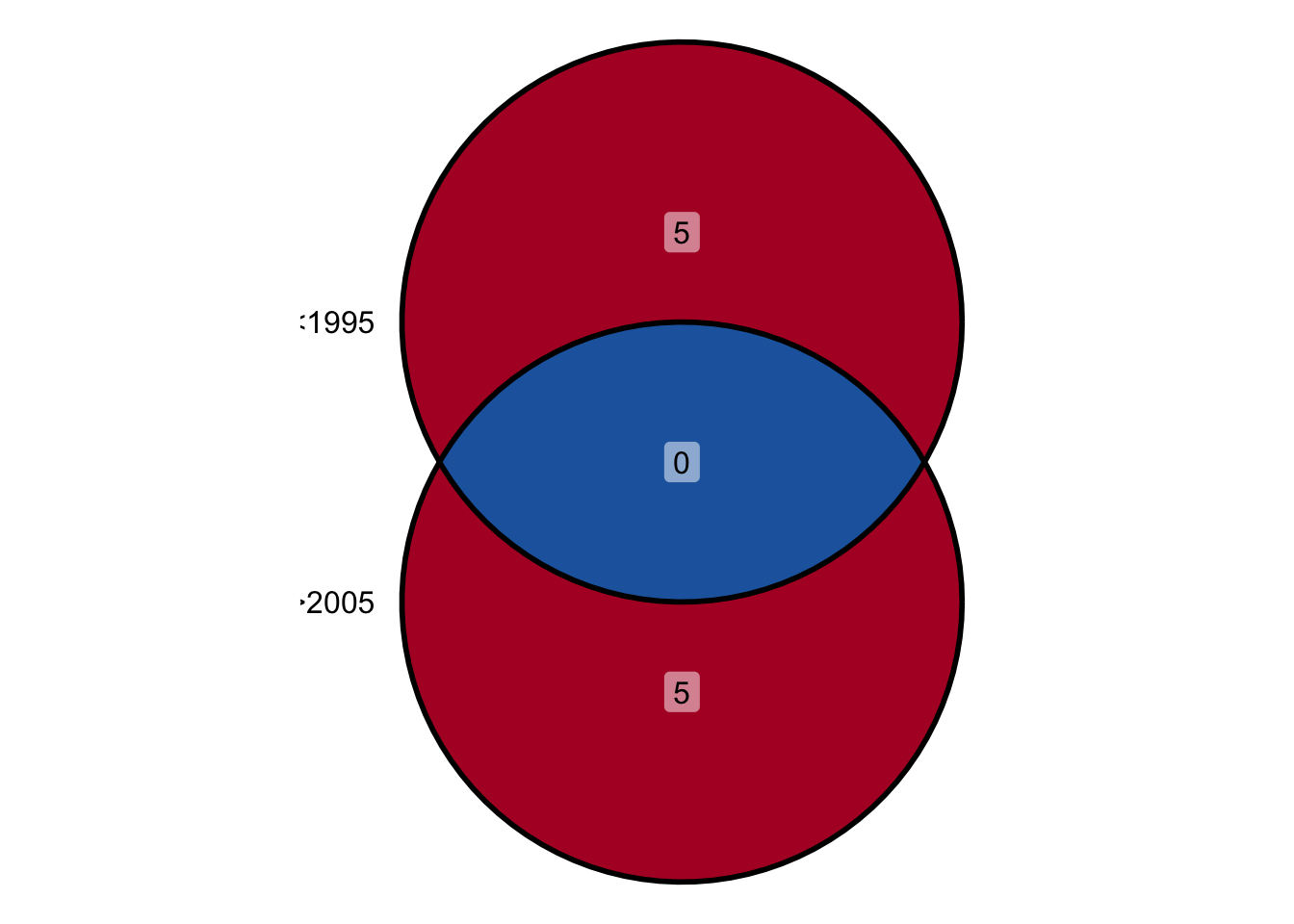 このケースでは,2つの条件のどちらも満たす
このケースでは,2つの条件のどちらも満たす year は存在しませんので,実際には重なりはありません。
ここで,滅多に使わないですが,次の関係は知っておいてください。
## [1] NA## [1] TRUENA の取り扱いは難しいため,実際にコードを書くときには,コードを分解して,確実に意図通りの結果が得られていることを確かめながら,全体を完成させてください。
4.1.2 文字列
文字列の比較演算子が使えます。 文字列の比較演算は次のようにします。
prefecture <- c("北海道", "青森県", "岩手県", "宮城県", "秋田県", "山形県", "福島県",
"茨城県", "栃木県", "群馬県", "埼玉県", "千葉県", "東京都", "神奈川県",
"新潟県", "富山県", "石川県", "福井県", "山梨県", "長野県", "岐阜県", "静岡県", "愛知県",
"三重県", "滋賀県", "京都府", "大阪府", "兵庫県", "奈良県", "和歌山県",
"鳥取県", "島根県", "岡山県", "広島県", "山口県", "徳島県", "香川県", "愛媛県", "高知県",
"福岡県", "佐賀県", "長崎県", "熊本県", "大分県", "宮崎県", "鹿児島県", "沖縄県")
prefecture[prefecture == "愛媛県"]## [1] "愛媛県"数値と同じく,文字列の返り値も論理値です。
文字列の場合,== は完全一致を意味します。
prefecture[prefecture == "愛媛県"] の例はあまり意味がありません。
しかし,prefecture == "愛媛県" の部分は重要です。
次のコマンドの返り値がどうなるかをよく知っておいてください。
## [1] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
## [13] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
## [25] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
## [37] FALSE TRUE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE文字列の場合,大きさはないため,> や < といった比較演算子は使えないはずです。
## [1] "北海道" "青森県" "岩手県" "宮城県" "秋田県" "山形県" "福島県"
## [8] "茨城県" "栃木県" "群馬県" "埼玉県" "千葉県" "東京都" "神奈川県"
## [15] "新潟県" "富山県" "石川県" "福井県" "山梨県" "長野県" "岐阜県"
## [22] "静岡県" "三重県" "滋賀県" "京都府" "大阪府" "兵庫県" "奈良県"
## [29] "和歌山県" "鳥取県" "島根県" "岡山県" "広島県" "山口県" "徳島県"
## [36] "香川県" "高知県" "福岡県" "佐賀県" "長崎県" "熊本県" "大分県"
## [43] "宮崎県" "鹿児島県" "沖縄県"## [1] "愛知県"予想に反して,返り値はエラーではありません。 これは,各文字列の文字コードを比較しています。 このことは,次のコマンドでも確認できます。
## [1] 北海道 青森県 岩手県 宮城県 秋田県 山形県 福島県 茨城県
## [9] 栃木県 群馬県 埼玉県 千葉県 東京都 神奈川県 新潟県 富山県
## [17] 石川県 福井県 山梨県 長野県 岐阜県 静岡県 愛知県 三重県
## [25] 滋賀県 京都府 大阪府 兵庫県 奈良県 和歌山県 鳥取県 島根県
## [33] 岡山県 広島県 山口県 徳島県 香川県 愛媛県 高知県 福岡県
## [41] 佐賀県 長崎県 熊本県 大分県 宮崎県 鹿児島県 沖縄県
## 47 Levels: 愛知県 愛媛県 茨城県 岡山県 沖縄県 岩手県 岐阜県 宮崎県 ... 和歌山県Levels がおかしな並び順になっていることが確認できます。
ここで R と RStudio では, levels(prefecture) が異なります。
なぜなのか?どなたか説明いただければ幸いです。RStudio は何をしているのでしょうか?
こうした文字コードでの順序づけを回避するには,levels() を明示的に指定しなければなりません。
## [1] 北海道 青森県 岩手県 宮城県 秋田県 山形県 福島県 茨城県
## [9] 栃木県 群馬県 埼玉県 千葉県 東京都 神奈川県 新潟県 富山県
## [17] 石川県 福井県 山梨県 長野県 岐阜県 静岡県 愛知県 三重県
## [25] 滋賀県 京都府 大阪府 兵庫県 奈良県 和歌山県 鳥取県 島根県
## [33] 岡山県 広島県 山口県 徳島県 香川県 愛媛県 高知県 福岡県
## [41] 佐賀県 長崎県 熊本県 大分県 宮崎県 鹿児島県 沖縄県
## 47 Levels: 北海道 < 青森県 < 岩手県 < 宮城県 < 秋田県 < 山形県 < ... < 沖縄県## [1] 高知県 福岡県 佐賀県 長崎県 熊本県 大分県 宮崎県 鹿児島県
## [9] 沖縄県
## 47 Levels: 北海道 < 青森県 < 岩手県 < 宮城県 < 秋田県 < 山形県 < ... < 沖縄県このようなこともできますが,特別な理由がない限り,文字列の大小比較はしないでください。
さて,文字列のベクトルの中から共通する要素を取り出したいことがあるかもしれません。 例えば,都道府県の中から府のみを取り出したいときに,次のようにしても得たい結果は得られません。
## character(0)上述のように,== は完全一致を意味するからです。
このとき,次のようにします。
## [1] "京都府" "大阪府"これは正規表現を使った抽出です。 このコマンドはやや冗長で,本来なら次のようにすべきです。
## [1] "京都府" "大阪府"grep は正規表現を使った処理ができる関数のひとつです。
ただし,正規表現の理解は初学者には難しいでしょう。
4.1.3 正規表現
正規表現を知っているかどうかで,比較演算子の効率的な使い方が飛躍的に向上します。 正規表現は,人間が考えるかのようにコンピュータに考えさせる記述方法です。 しかし,非常にややこしいので,最初は覚える必要はありません。
Rをある程度使えるようになったら,以下のWebページを確認してください。
4.2 条件分岐
条件分岐とは,「もし〜ならば」という条件「〜」を満たす場合に,指定の処理をする手続きのことです。
## [1] "正解です。"このように,if と () の間にスペースを入れます。
また,{} の前後は改行し,{} の中は左にインデントを付けるようにしてください。
インデントは,スペース2つが一般的です(スペースを4つ付ける人もいます)。
if 文は,「そうでなければ」ということを意味する else を伴うこともできます。
## [1] "正解です。"## [1] "正解です。"if 文の () の中は,長さ1のベクトル(スカラーではない)かつ論理値でなければなりません。
すなわち,if 文の () の中は TRUE か FALSE です。
もしベクトルの要素1つずつ処理したい場合は,次に説明する繰り返し処理と組み合わせて使います。
4.3 繰り返し処理
## [1] 11このように,for と () の間にスペースを入れます。
また,for 文と同じように,{} の前後は改行し,{} の中は左にインデントを付けるようにしてください。
for 文を使うときは,必ずループから抜け出せるようにしてください。
例えば,for の引数に {} の中で代入した場合,無限ループになることがあります。
繰り返し処理には,for 文意外に while 文もあります。
4.4 データ・クリーニング
よく使う関数に次のようなものがある。
例えば,次のように使う。
##
## setosa versicolor virginica
## 50 50 50## [1] setosa versicolor virginica
## Levels: setosa versicolor virginica## [1] 132 118 119 123 136 106 131 108 110 126 130 103 51 53 121 140 142 77 113
## [20] 144 66 78 87 109 125 141 145 146 59 76 55 105 111 117 148 52 75 112
## [39] 116 129 133 138 57 73 88 101 104 124 134 137 147 69 98 127 149 64 72
## [58] 74 92 128 135 63 79 84 86 120 139 62 71 150 15 68 83 93 102 115
## [77] 143 16 19 56 80 96 97 100 114 65 67 70 89 95 122 34 37 54 81
## [96] 82 90 91 6 11 17 21 32 85 49 28 29 33 60 1 18 20 22 24
## [115] 40 45 47 99 5 8 26 27 36 41 44 50 61 94 2 10 35 38 58
## [134] 107 12 13 25 31 46 3 30 4 7 23 48 42 9 39 43 14## Sepal.Length Sepal.Width Petal.Length Petal.Width Species
## 132 7.9 3.8 6.4 2.0 virginica
## 118 7.7 3.8 6.7 2.2 virginica
## 119 7.7 2.6 6.9 2.3 virginica
## 123 7.7 2.8 6.7 2.0 virginica
## 136 7.7 3.0 6.1 2.3 virginica
## 106 7.6 3.0 6.6 2.1 virginica論理式での数値は,0 のみが FALSE として扱われ,それ以外は TRUE として扱われます。
## [1] TRUE## [1] FALSE4.5 関数の作成
関数を自分で作ることができます。
connect_with_slash <- function (y) {
paste(y, collapse = "/")
}
connect_with_slash(c("Apple", "Orange"))## [1] "Apple/Orange"4.6 練習問題
- 次のデータフレーム
zがあるとする。zを使って,2000年以降のvalueの値の平均を求めなさい。基礎の練習問題と同じです。ただし,ここでは比較演算子を用いなさい。
九九(1から9までの整数同士の掛け算)のすべての組み合わせの答えを合計しなさい。
「北海道」「青森」…「東京」…といった都道府県のベクトル
prefがあります。北海道には「道」の文字が付いていますが,都府県には「都」「府」「県」の文字が付いていません。そこで,都府県にも「都府県」を付けて,すべてのデータが「都道府県」で終わるように揃えたいとします。ただし,データの中には47都道府県がすべて含まれているかどうか,重複があるかどうかは分かりません。すべての文字列が「都道府県」で終わるように揃えなさい。ポケモンの中から,water タイプのポケモンをすべて挙げなさい。 ただし,ポケモンのデータセットは,
d3poパッケージのpokemonを使いなさい。