ここでは,農業協同組合の組合員数の推移の把握を試みます。
これまで,e-Statから取得したデータをグラフにするまで,何の迷いもなくRのコードを書いているかのように,説明してきました。 しかし実際には,図をどう描くか考える前に,データがどのような構造になっているのかを調べ,試行錯誤しています。 ここでは,統計データを取得した後,そのデータの構造を確認しながら,データを整形していく方法を紹介します。
e-Statからデータ取得
次のコードを実行し,欲しいデータを取得しましょう。 次のコードにある statsDataId = "0003406360" の数字はアクセスしたい統計データのIDです。
このサービスは、政府統計総合窓口(e-Stat)のAPI機能を使用していますが、サービスの内容は国によって保証されたものではありません。
appId <- keyring::key_get("e-stat")
statsDataId <- "0003406360"
(meta_info <- estat_getMetaInfo(appId = appId, statsDataId = statsDataId))
$cat01
# A tibble: 27 × 5
`@code` `@name` `@level` `@unit` `@parentCode`
<chr> <chr> <chr> <chr> <chr>
1 110 合計_計 1 人 <NA>
2 120 合計_個人 2 人 110
3 130 合計_団体 2 人 110
4 150 正組合員_計 2 人 110
5 160 正組合員_個人 3 人 150
6 170 正組合員_個人_女性 4 人 160
7 180 正組合員_個人_組合員たる地位を失わな… 4 人 160
8 190 正組合員_法人 3 人 150
9 200 正組合員_法人_農事組合法人 4 人 190
10 210 正組合員_法人_その他法人 4 人 190
# ℹ 17 more rows
$area
# A tibble: 56 × 4
`@code` `@name` `@level` `@parentCode`
<chr> <chr> <chr> <chr>
1 00000 全国 1 <NA>
2 00200 1組合当たり 1 <NA>
3 01000 北海道 2 00000
4 01100 東北_小計 2 00000
5 02000 青森県 3 01100
6 03000 岩手県 3 01100
7 04000 宮城県 3 01100
8 05000 秋田県 3 01100
9 06000 山形県 3 01100
10 07000 福島県 3 01100
# ℹ 46 more rows
$time
# A tibble: 19 × 3
`@code` `@name` `@level`
<chr> <chr> <chr>
1 2016100000 2016年度 1
2 2015100000 2015年度 1
3 2014100000 2014年度 1
4 2013100000 2013年度 1
5 2012100000 2012年度 1
6 2011100000 2011年度 1
7 2010100000 2010年度 1
8 2009100000 2009年度 1
9 2008100000 2008年度 1
10 2007100000 2007年度 1
11 2006100000 2006年度 1
12 2005100000 2005年度 1
13 2004100000 2004年度 1
14 2003100000 2003年度 1
15 2002100000 2002年度 1
16 2001100000 2001年度 1
17 2000100000 2000年度 1
18 1999100000 1999年度 1
19 1998100000 1998年度 1
$.names
# A tibble: 3 × 2
id name
<chr> <chr>
1 cat01 組合員別内訳
2 area 都道府県
3 time 時間軸(年度次)
# 統計データ取得
df <- estat_getStatsData(
appId = appId,
statsDataId = statsDataId
)
Fetching record 1-14009... (total: 14009 records)
# A tibble: 14,009 × 9
cat01_code 組合員別内訳 area_code 都道府県 time_code `時間軸(年度次)` unit
<chr> <chr> <chr> <chr> <chr> <chr> <chr>
1 110 合計_計 00000 全国 20161000… 2016年度 人
2 110 合計_計 00000 全国 20151000… 2015年度 人
3 110 合計_計 00000 全国 20141000… 2014年度 人
4 110 合計_計 00000 全国 20131000… 2013年度 人
5 110 合計_計 00000 全国 20121000… 2012年度 人
6 110 合計_計 00000 全国 20111000… 2011年度 人
7 110 合計_計 00000 全国 20101000… 2010年度 人
8 110 合計_計 00000 全国 20091000… 2009年度 人
9 110 合計_計 00000 全国 20081000… 2008年度 人
10 110 合計_計 00000 全国 20071000… 2007年度 人
# ℹ 13,999 more rows
# ℹ 2 more variables: value <dbl>, annotation <chr>
このデータはどういう構造になっているのか想像できない。 そこで,データの構造を詳細に確認してみる。
データ整形
データの構造を確認するには,次のコマンドを実行するとよいでしょう。 先頭のみを表示します。
# A tibble: 6 × 9
cat01_code 組合員別内訳 area_code 都道府県 time_code `時間軸(年度次)` unit
<chr> <chr> <chr> <chr> <chr> <chr> <chr>
1 110 合計_計 00000 全国 2016100000 2016年度 人
2 110 合計_計 00000 全国 2015100000 2015年度 人
3 110 合計_計 00000 全国 2014100000 2014年度 人
4 110 合計_計 00000 全国 2013100000 2013年度 人
5 110 合計_計 00000 全国 2012100000 2012年度 人
6 110 合計_計 00000 全国 2011100000 2011年度 人
# ℹ 2 more variables: value <dbl>, annotation <chr>
先頭の全体を表示したい場合は,tibble は不向きです。 不便だと思ったら,data.frame に変換するとよいでしょう。
cat01_code 組合員別内訳 area_code 都道府県 time_code 時間軸.年度次. unit
1 110 合計_計 00000 全国 2016100000 2016年度 人
2 110 合計_計 00000 全国 2015100000 2015年度 人
3 110 合計_計 00000 全国 2014100000 2014年度 人
4 110 合計_計 00000 全国 2013100000 2013年度 人
5 110 合計_計 00000 全国 2012100000 2012年度 人
6 110 合計_計 00000 全国 2011100000 2011年度 人
value annotation
1 10444426 <NA>
2 10370172 <NA>
3 10267614 <NA>
4 10145363 <NA>
5 9977967 <NA>
6 9834031 <NA>
データの最後の部分のみを表示します。
# A tibble: 6 × 9
cat01_code 組合員別内訳 area_code 都道府県 time_code `時間軸(年度次)` unit
<chr> <chr> <chr> <chr> <chr> <chr> <chr>
1 380 一戸複数正組… 47000 沖縄県 20081000… 2008年度 組合
2 380 一戸複数正組… 47000 沖縄県 20071000… 2007年度 組合
3 380 一戸複数正組… 47000 沖縄県 20061000… 2006年度 組合
4 380 一戸複数正組… 47000 沖縄県 20051000… 2005年度 組合
5 380 一戸複数正組… 47000 沖縄県 20041000… 2004年度 組合
6 380 一戸複数正組… 47000 沖縄県 20031000… 2003年度 組合
# ℹ 2 more variables: value <dbl>, annotation <chr>
データの次元(列数とレコード数)を確認します。
データの構造を確認します。
tibble [14,009 × 9] (S3: tbl_df/tbl/data.frame)
$ cat01_code : chr [1:14009] "110" "110" "110" "110" ...
$ 組合員別内訳 : chr [1:14009] "合計_計" "合計_計" "合計_計" "合計_計" ...
$ area_code : chr [1:14009] "00000" "00000" "00000" "00000" ...
$ 都道府県 : chr [1:14009] "全国" "全国" "全国" "全国" ...
$ time_code : chr [1:14009] "2016100000" "2015100000" "2014100000" "2013100000" ...
$ 時間軸(年度次): chr [1:14009] "2016年度" "2015年度" "2014年度" "2013年度" ...
$ unit : chr [1:14009] "人" "人" "人" "人" ...
$ value : num [1:14009] 10444426 10370172 10267614 10145363 9977967 ...
$ annotation : chr [1:14009] NA NA NA NA ...
まず,「都道府県」の列に「全国」があるのが確認できます。 最初は,"全国" の行だけ抽出することに決め。都道府県別については後回しにすることにします。 こうしたデータ抽出の判断は,人間が行わなければなりません。
データフレームのそれぞれの列にどういう値が入っているか確認するには,文字列型の場合,table() または unique() を使えばよいです。
1組合当たり 愛知県 愛媛県 茨城県 岡山県
249 249 249 249 249
沖縄県 関東_小計 岩手県 岐阜県 宮崎県
249 249 249 249 249
宮城県 京都府 近畿_小計 九州_小計 熊本県
249 249 249 249 249
群馬県 広島県 香川県 高知県 佐賀県
249 249 249 249 249
埼玉県 三重県 山形県 山口県 山梨県
249 249 249 249 249
滋賀県 鹿児島県 秋田県 新潟県 神奈川県
249 249 249 249 249
青森県 静岡県 石川県 千葉県 全国
249 249 249 249 314
大阪府 大分県 中国・四国_小計 長崎県 長野県
249 249 249 249 249
鳥取県 島根県 東海_小計 東京都 東北_小計
249 249 249 249 249
徳島県 栃木県 奈良県 富山県 福井県
249 249 249 249 249
福岡県 福島県 兵庫県 北海道 北陸_小計
249 249 249 249 249
和歌山県
249
[1] "全国" "1組合当たり" "北海道" "東北_小計"
[5] "青森県" "岩手県" "宮城県" "秋田県"
[9] "山形県" "福島県" "関東_小計" "茨城県"
[13] "栃木県" "群馬県" "埼玉県" "千葉県"
[17] "東京都" "神奈川県" "山梨県" "長野県"
[21] "静岡県" "北陸_小計" "新潟県" "富山県"
[25] "石川県" "福井県" "東海_小計" "岐阜県"
[29] "愛知県" "三重県" "近畿_小計" "滋賀県"
[33] "京都府" "大阪府" "兵庫県" "奈良県"
[37] "和歌山県" "中国・四国_小計" "鳥取県" "島根県"
[41] "岡山県" "広島県" "山口県" "徳島県"
[45] "香川県" "愛媛県" "高知県" "九州_小計"
[49] "福岡県" "佐賀県" "長崎県" "熊本県"
[53] "大分県" "宮崎県" "鹿児島県" "沖縄県"
table() と unique() は似た結果が出力されます。 table() からはそれぞれのレコード数が分かり,unique() からは表にある順番が分かります。
ここでは,"全国" だけで 314 もある。
データフレームの列
ここでデータフレームの列の指定方法について,簡単に説明しておきます。 最も簡単かつ短い書き方は次のとおりです。
ただし,日本語の列名をそのまま使うのは不安です。 例えば,次のようにするとエラーが出ます。
なぜでしょうか。 Rを使い慣れている人だとこの種のエラーへの対策は分かるはずです。 例えば,データフレームがこの列名を変えたがることに気づいたことがあるでしょう。 そう,data.frame() で指定する check.names = はこうした問題に対応するための引数です。
こうしたエラーの回避策はあります。 次のようにするとエラーが出ず,欲しい結果が得られます。
ただし,こういった書き方をするくらいであれば,df[, "時間軸(年度次)"] といった表記に統一した方がスマートではないでしょうか。 しかし,この表記はtidyverse(tibble)的には好ましくないようである。 base Rでは,[]内がスカラー(1次元)なら返り値はベクトルで,[]内がベクトル(2次元以上)なら返り値はデータフレームです。 tibbleの場合,[]内が何であれ,返り値はtibbleになるようです。
df[, "時間軸(年度次)"]
data.frame(df, check.names = FALSE)[, "時間軸(年度次)"]
データフレームの列間関係
head(df)の返り値を詳細に見てみましょう。 area_code が "00000" である行は,"全国" に対応していることが想像できます。 本当にそうなっているか,確認してみましょう。
table(df$area_code, df$都道府県)
このようにしてもよいですが,出力が大きすぎるため,ピンポイントで結果が得られるコードを書く必要があります。
table(df$area_code[df$都道府県 == "全国"])
df[df$都道府県 != "全国" & df$area_code == "00000", ]
# A tibble: 0 × 9
# ℹ 9 variables: cat01_code <chr>, 組合員別内訳 <chr>, area_code <chr>,
# 都道府県 <chr>, time_code <chr>, 時間軸(年度次) <chr>, unit <chr>,
# value <dbl>, annotation <chr>
次に,時間軸(年度次) 列がそのまま年度が入力されていることが創造できます。 そして,"2016年度","2015年度","2014年度" といったように文字列となっていることから,"年度" を削除して,数値型に変換する必要があることまで見通せます。 一方,time_code 列は,"2016100000","2015100000","2014100000" という値が入っており,文字列です。 これが 時間軸(年度次) 列と同じ情報かどうかは,これだけでは分かりません。 "2016" に続く "100000" の数字は何を意味するのでしょうか。 time_code 列を確認してみます。
1998100000 1999100000 2000100000 2001100000 2002100000 2003100000 2004100000
13 13 13 13 13 728 728
2005100000 2006100000 2007100000 2008100000 2009100000 2010100000 2011100000
728 728 1176 1176 1176 1176 1008
2012100000 2013100000 2014100000 2015100000 2016100000
1064 1064 1064 1064 1064
time_code 列の値の後半部分 "100000" は,ここでは意味がなく,sub() で削除してもよいことが創造できます。 それでは,time_code 列は 時間軸(年度次) 列と1対1で対応しているでしょうか。 すなわち,時間軸(年度次) 列から"年度" を取り除いた値とtime_code 列から"100000"を取り除いた値は一致するでしょうか。 これを確認する方法は多くあります。 例えば,次のようにします。
table(apply(df[, c("time_code", "時間軸(年度次)")], 1, paste, collapse = " "))
1998100000 1998年度 1999100000 1999年度 2000100000 2000年度 2001100000 2001年度
13 13 13 13
2002100000 2002年度 2003100000 2003年度 2004100000 2004年度 2005100000 2005年度
13 728 728 728
2006100000 2006年度 2007100000 2007年度 2008100000 2008年度 2009100000 2009年度
728 1176 1176 1176
2010100000 2010年度 2011100000 2011年度 2012100000 2012年度 2013100000 2013年度
1176 1008 1064 1064
2014100000 2014年度 2015100000 2015年度 2016100000 2016年度
1064 1064 1064
ただし,この方法では結果をいちいち確認しなければなりません。 できれば,TRUE で返ってくるかどうかで判断したいです。 もしそうなら,次のようにすればよいです。
table(sub("年度", "", df$`時間軸(年度次)`) == sub("100000$", "", df$time_code))
年度の入力ミスはなさそうなので,どちらの列でもよく,今回は 時間軸(年度次) 列から年度の数値が得られることが分かります。
str(df)の返り値について,他の列について見ておきましょう。 unit 列は単位であり作図には使いませんが,数値の意味を確認する際に参照することを覚えておきます。 value は数値です。 この表はロングであるため,ggplot2 として作図するのに扱いやすいです。
データフレームの整形
これまででデータの構造がおおよそ把握できました。 ここで,データを扱いやすくなるように変更します。
その際,元のデータフレームは残したまま,新しいデータフレームを作成するようにしましょう。 以降は新しいデータフレームで作業し,もし間違った場合は,ここに戻ってくれば最初からやり直さずににすむためです。
まず,全国のみのデータを抽出してもよいですが,後で都道府県別のデータを扱うときに手間をかけないようにするために,全国のみのデータにするのは最後にしましょう。 それ以外の整形をまずやります。
df2 <- df
df2$年度 <- as.double(sub("年度", "", df2$`時間軸(年度次)`))
## 必要な列のみ抽出すると視認性は高まるが,Rとしてはこのようにするメリットはない
# df2 <- df2[, c("組合員別内訳", "都道府県", "年度", "unit", "value")]
いよいよ 組合員別内訳 列に何が入っているか確認します。
unique(data.frame(df2[, "組合員別内訳"]))
組合員別内訳
1 合計_計
790 合計_個人
1579 合計_団体
2368 正組合員_計
3157 正組合員_個人
3946 正組合員_個人_女性
4735 正組合員_個人_組合員たる地位を失わない者
5015 正組合員_法人
5351 正組合員_法人_農事組合法人
5687 正組合員_法人_その他法人
6023 正組合員_団体
6476 正組合員_団体_農事組合法人
6700 正組合員_団体_株式会社
6924 正組合員_団体_合名会社
7148 正組合員_団体_合資会社
7372 正組合員戸数
8161 准組合員_計
8950 准組合員_個人
9739 准組合員_団体
10528 准組合員_団体_農業協同組合
10864 准組合員_団体_農事組合法人
11424 准組合員_団体_その他団体
11760 准組合員_団体_株式会社
11984 准組合員_団体_合名会社
12208 准組合員_団体_合資会社
12432 准組合員戸数
13221 一戸複数正組合員制実施組合数
ここで,この列が正組合員と准組合員といった分類であることが分かります。 念のため,ここで unit 列との対応を確認しておきます。
table(apply(df2[, c("組合員別内訳", "unit")], 1, paste, collapse = " "))
一戸複数正組合員制実施組合数 組合
789
合計_計 人
789
合計_個人 人
789
合計_団体 人
789
准組合員_計 人
789
准組合員_個人 人
789
准組合員_団体 人
789
准組合員_団体_その他団体 人
336
准組合員_団体_株式会社 人
224
准組合員_団体_合資会社 人
224
准組合員_団体_合名会社 人
224
准組合員_団体_農業協同組合 人
336
准組合員_団体_農事組合法人 人
560
准組合員戸数 戸
789
正組合員_計 人
789
正組合員_個人 人
789
正組合員_個人_女性 人
789
正組合員_個人_組合員たる地位を失わない者 人
280
正組合員_団体 人
453
正組合員_団体_株式会社 人
224
正組合員_団体_合資会社 人
224
正組合員_団体_合名会社 人
224
正組合員_団体_農事組合法人 人
224
正組合員_法人 人
336
正組合員_法人_その他法人 人
336
正組合員_法人_農事組合法人 人
336
正組合員戸数 戸
789
法人も単位は "人" になっているようです。 "組合" と "戸" だけ注意すべきでしょう。
ここで,見栄えをよくするために,アンダーバーを括弧に変換しておきます。 これらの値が作図する際の凡例に表示されることがあるため,見栄えは重要です。
# _を()に変換する(factorではない場合)
df2[, "組合員別内訳"] <- apply(df2[, "組合員別内訳", drop = FALSE], 1, function(x) {
if (length(grep("_", x)) > 0) {
x <- paste0(sub("_", "(", x), ")")
}
return(x)}
)
# _を2つ使っているケースに対応
df2[, "組合員別内訳"] <- apply(df2[, "組合員別内訳", drop = FALSE], 1, function(x) {
if (length(grep("_", x)) > 0) {
x <- paste0(sub("_", "(", x), ")")
}
return(x)}
)
unique(df2[, "組合員別内訳"])
# A tibble: 27 × 1
組合員別内訳
<chr>
1 合計(計)
2 合計(個人)
3 合計(団体)
4 正組合員(計)
5 正組合員(個人)
6 正組合員(個人(女性))
7 正組合員(個人(組合員たる地位を失わない者))
8 正組合員(法人)
9 正組合員(法人(農事組合法人))
10 正組合員(法人(その他法人))
# ℹ 17 more rows
df2$組合員別内訳 <- factor(df2$組合員別内訳, levels = unique(df2$組合員別内訳))
最後に,全国のデータを抽出する。
df3 <- df2[df2$都道府県 == "全国", ]
作図
作図のためには,ここまでで整形したデータフレームから,作図に必要な行を抽出すればよいです。
折れ線グラフの作図
まず,組合員の合計の折れ線グラフを描くことにしましょう。 必要なデータのみを抽出します。 grep() の最初の引数は正規表現です。 正規表現は初心者にはハードルが高いですが,慣れると非常に便利です。
df_JAmembers <- df3[grep("^合計(計)$", df3$組合員別内訳), ]
df_JAmembers
# A tibble: 19 × 10
cat01_code 組合員別内訳 area_code 都道府県 time_code `時間軸(年度次)` unit
<chr> <fct> <chr> <chr> <chr> <chr> <chr>
1 110 合計(計) 00000 全国 20161000… 2016年度 人
2 110 合計(計) 00000 全国 20151000… 2015年度 人
3 110 合計(計) 00000 全国 20141000… 2014年度 人
4 110 合計(計) 00000 全国 20131000… 2013年度 人
5 110 合計(計) 00000 全国 20121000… 2012年度 人
6 110 合計(計) 00000 全国 20111000… 2011年度 人
7 110 合計(計) 00000 全国 20101000… 2010年度 人
8 110 合計(計) 00000 全国 20091000… 2009年度 人
9 110 合計(計) 00000 全国 20081000… 2008年度 人
10 110 合計(計) 00000 全国 20071000… 2007年度 人
11 110 合計(計) 00000 全国 20061000… 2006年度 人
12 110 合計(計) 00000 全国 20051000… 2005年度 人
13 110 合計(計) 00000 全国 20041000… 2004年度 人
14 110 合計(計) 00000 全国 20031000… 2003年度 人
15 110 合計(計) 00000 全国 20021000… 2002年度 人
16 110 合計(計) 00000 全国 20011000… 2001年度 人
17 110 合計(計) 00000 全国 20001000… 2000年度 人
18 110 合計(計) 00000 全国 19991000… 1999年度 人
19 110 合計(計) 00000 全国 19981000… 1998年度 人
# ℹ 3 more variables: value <dbl>, annotation <chr>, 年度 <dbl>
これは,tidyverseでは次のように書きます。
以下のオブジェクトは 'package:stats' からマスクされています:
filter, lag
以下のオブジェクトは 'package:base' からマスクされています:
intersect, setdiff, setequal, union
df_JAmembers <- df3 |>
filter(grepl("^合計(計)$", 組合員別内訳))
df_JAmembers
# A tibble: 19 × 10
cat01_code 組合員別内訳 area_code 都道府県 time_code `時間軸(年度次)` unit
<chr> <fct> <chr> <chr> <chr> <chr> <chr>
1 110 合計(計) 00000 全国 20161000… 2016年度 人
2 110 合計(計) 00000 全国 20151000… 2015年度 人
3 110 合計(計) 00000 全国 20141000… 2014年度 人
4 110 合計(計) 00000 全国 20131000… 2013年度 人
5 110 合計(計) 00000 全国 20121000… 2012年度 人
6 110 合計(計) 00000 全国 20111000… 2011年度 人
7 110 合計(計) 00000 全国 20101000… 2010年度 人
8 110 合計(計) 00000 全国 20091000… 2009年度 人
9 110 合計(計) 00000 全国 20081000… 2008年度 人
10 110 合計(計) 00000 全国 20071000… 2007年度 人
11 110 合計(計) 00000 全国 20061000… 2006年度 人
12 110 合計(計) 00000 全国 20051000… 2005年度 人
13 110 合計(計) 00000 全国 20041000… 2004年度 人
14 110 合計(計) 00000 全国 20031000… 2003年度 人
15 110 合計(計) 00000 全国 20021000… 2002年度 人
16 110 合計(計) 00000 全国 20011000… 2001年度 人
17 110 合計(計) 00000 全国 20001000… 2000年度 人
18 110 合計(計) 00000 全国 19991000… 1999年度 人
19 110 合計(計) 00000 全国 19981000… 1998年度 人
# ℹ 3 more variables: value <dbl>, annotation <chr>, 年度 <dbl>
tidyverseの方が分かりやすいとの評判ですが,個人的にはどちらでも同じです。 tidyverseの方がコードが短くなることはよくあります。
library(ggplot2)
library(scales)
library(ggsci)
df_JAmembers$組合員別内訳 <- droplevels(df_JAmembers$組合員別内訳)
g <- ggplot(data = df_JAmembers, aes(x = 年度, y = value, group = 組合員別内訳, colour = 組合員別内訳)) +
geom_line() +
geom_point() +
scale_y_continuous(labels = scales::comma, name = "組合員数") +
ggtitle("農業協同組合の組合員数の推移") +
labs(caption = "出所:農林水産省『農業協同組合及び同連合会一斉調査 確報 総合農協統計表』\n(https://www.e-stat.go.jp/dbview?sid=0003406360)") +
theme_bw() +
scale_color_d3()
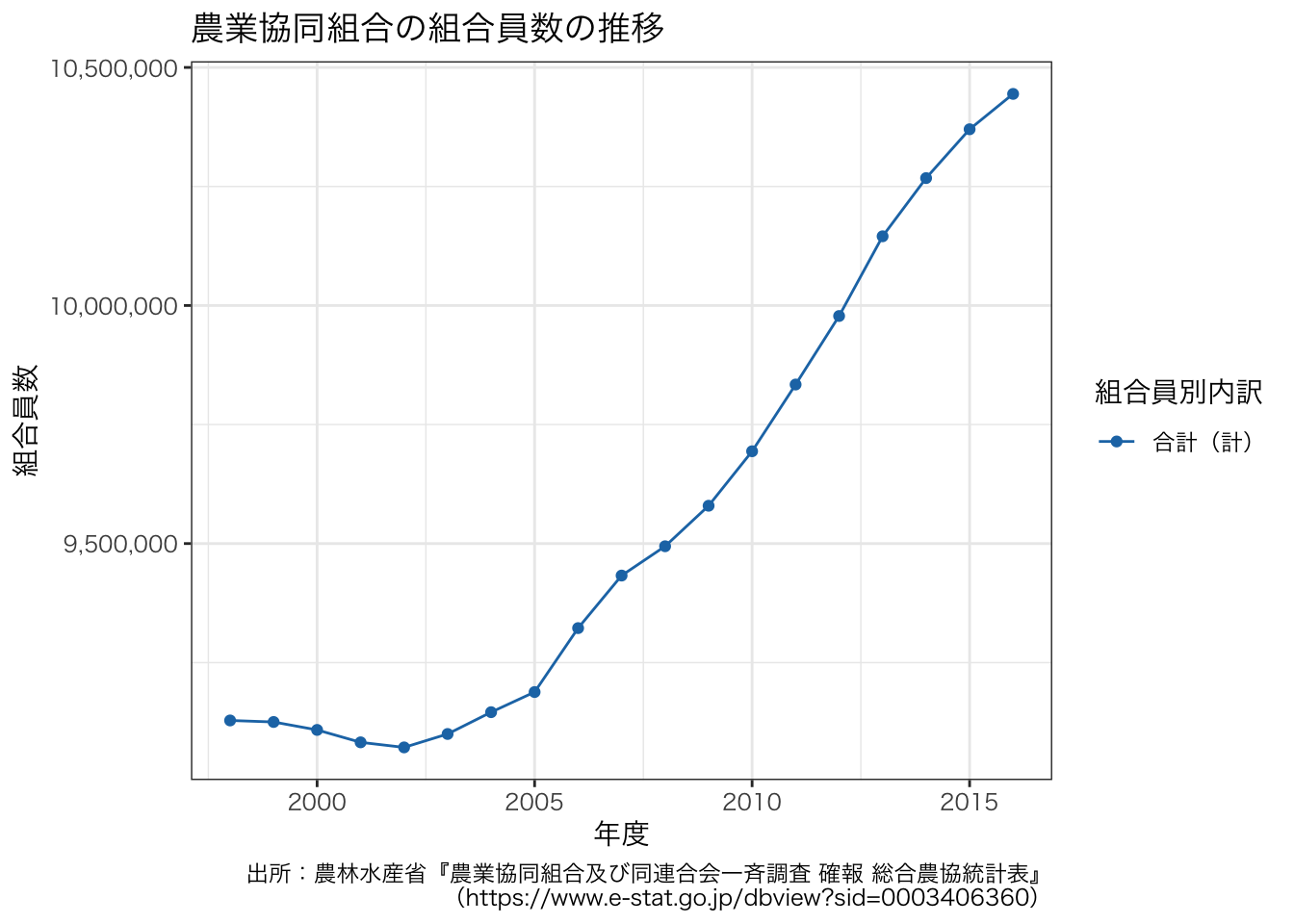
g + theme(text = element_text(family = "HiraKakuProN-W3"))
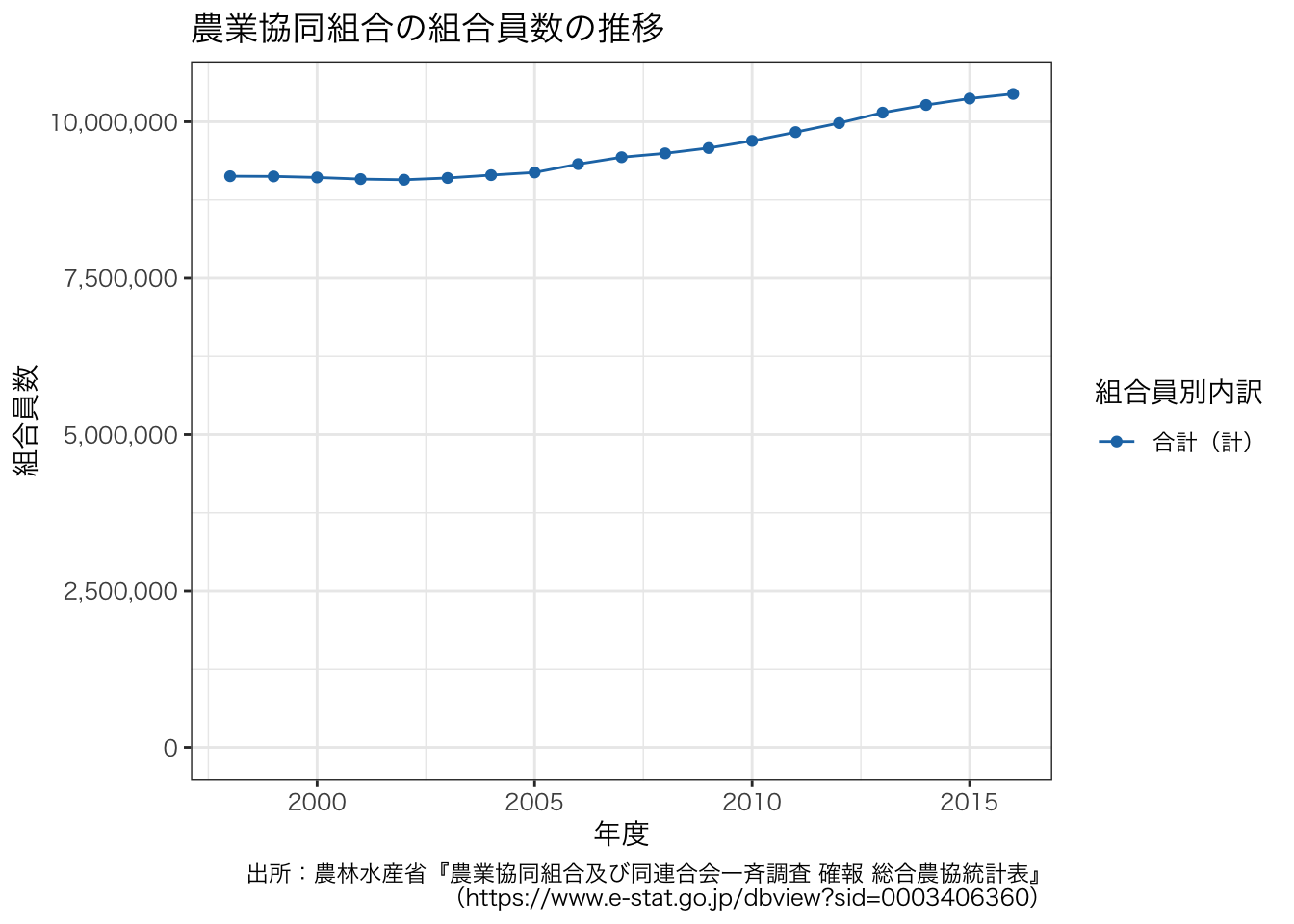
組合員数が極端に増加しているように見えます。 これはこれで間違っていないが,気になるようなら,縦軸が0から始まるようにするとよいでしょう。
g <- ggplot(data = df_JAmembers, aes(x = 年度, y = value, group = 組合員別内訳, colour = 組合員別内訳)) +
geom_line() +
geom_point() +
scale_y_continuous(limits = c(0, NA), labels = scales::comma, name = "組合員数") +
ggtitle("農業協同組合の組合員数の推移") +
labs(caption = "出所:農林水産省『農業協同組合及び同連合会一斉調査 確報 総合農協統計表』\n(https://www.e-stat.go.jp/dbview?sid=0003406360)") +
theme_bw() +
scale_color_d3()
g + theme(text = element_text(family = "HiraKakuProN-W3"))
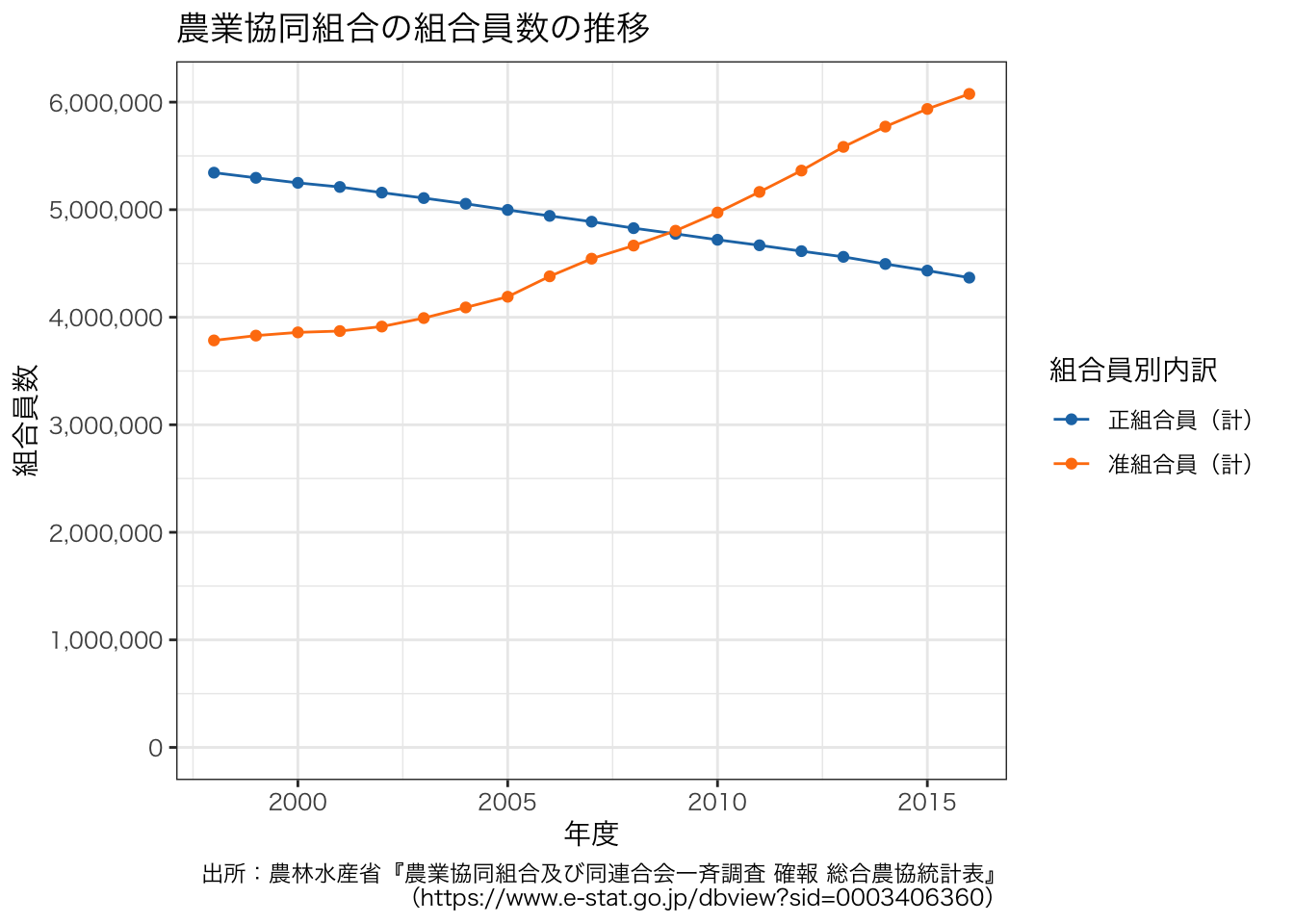
続いて,正組合員と准組合員の折れ線グラフを描いてみます。
df_JAmembers <- df3[grep("^正組合員(計)$|^准組合員(計)$", df3$組合員別内訳), ]
df_JAmembers$組合員別内訳 <- droplevels(df_JAmembers$組合員別内訳)
g <- ggplot(data = df_JAmembers, aes(x = 年度, y = value, group = 組合員別内訳, colour = 組合員別内訳)) +
geom_line() +
geom_point() +
scale_y_continuous(limits = c(0, NA), breaks = seq(0, 6000000, 1000000), labels = scales::comma, name = "組合員数") +
ggtitle("農業協同組合の組合員数の推移") +
labs(caption = "出所:農林水産省『農業協同組合及び同連合会一斉調査 確報 総合農協統計表』\n(https://www.e-stat.go.jp/dbview?sid=0003406360)") +
theme_bw() +
scale_color_d3()
g + theme(text = element_text(family = "HiraKakuProN-W3"))
正組合員と准組合員が逆転する折れ線グラフが描けました。
もっと作図
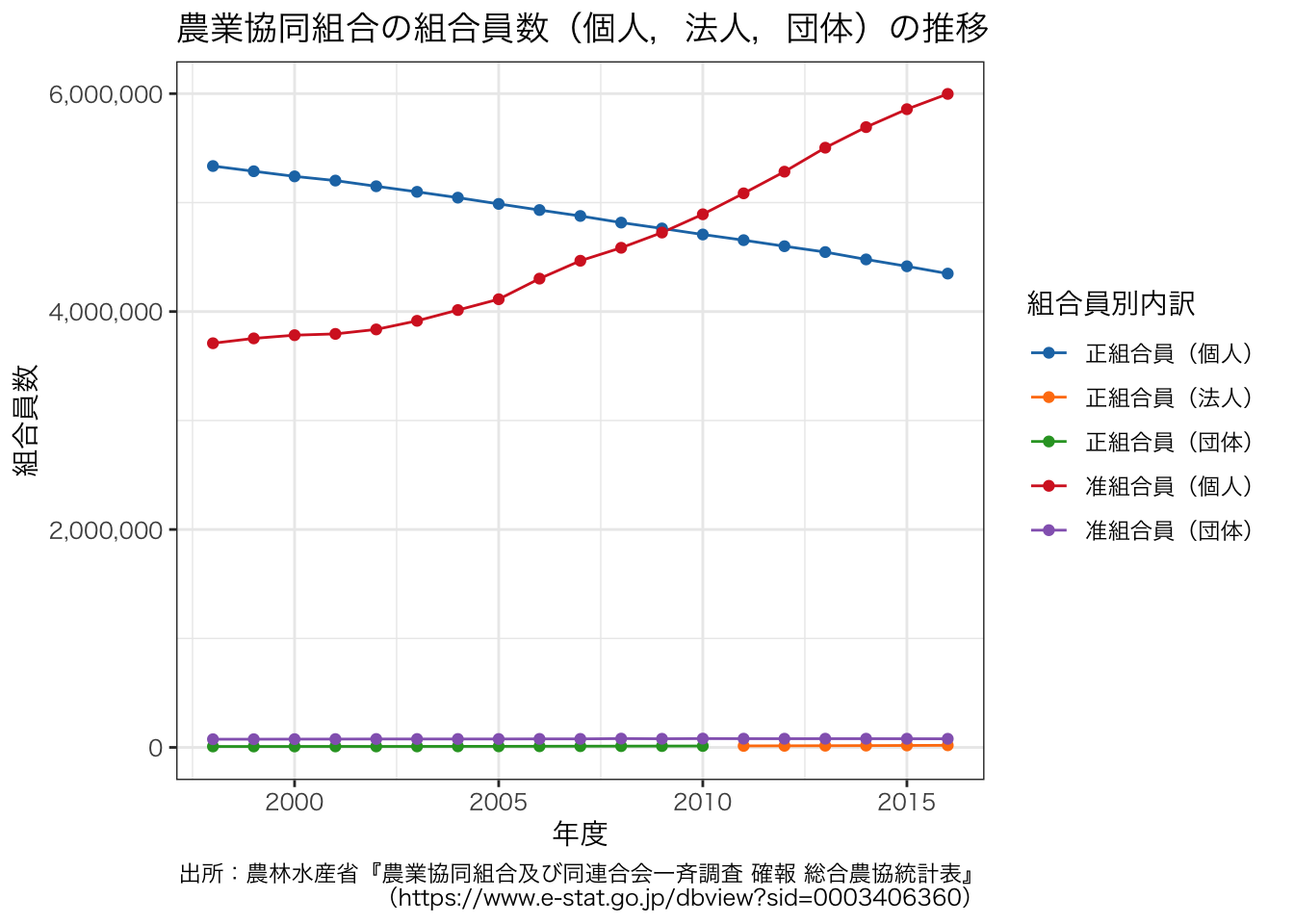
次に,個人以外の組合員についても見ていきましょう。
df_JAmembers <- df3[grep("^正組合員(個人)$|^正組合員(法人)$|^正組合員(団体)$|^准組合員(個人)$|^准組合員(団体)$", df3$組合員別内訳), ]
df_JAmembers$組合員別内訳 <- droplevels(df_JAmembers$組合員別内訳)
g <- ggplot(data = df_JAmembers, aes(x = 年度, y = value, group = 組合員別内訳, colour = 組合員別内訳)) +
geom_line() +
geom_point() +
scale_y_continuous(limits = c(0, NA), labels = scales::comma, name = "組合員数") +
ggtitle("農業協同組合の組合員数(個人,法人,団体)の推移") +
labs(caption = "出所:農林水産省『農業協同組合及び同連合会一斉調査 確報 総合農協統計表』\n(https://www.e-stat.go.jp/dbview?sid=0003406360)") +
theme_bw() +
scale_color_d3()
g + theme(text = element_text(family = "HiraKakuProN-W3"))
ggsave(file = "ja_members_kojin_dantai.pdf", plot = g, path = outdir, width = 8, height = 4)
正組合員(団体)のグラフが途中で消え,正組合員(法人)のグラフが途中から現れていることが気になります。 正組合員(団体)の値と正組合員(法人)の値が近いことから,統計の取り方が変わった可能性が考えられるでしょう。 そこで,元のデータで,正組合員(団体)が途中から欠損値になっているかどうかを確認してみます。 表を見る場合は,データをロングではなくワイドにした方が分かりやすいです。
library(tidyr)
df3_wide <- df3 |>
tidyr::pivot_wider(id_cols = 年度, names_from = 組合員別内訳, values_from = value)
knitr::kable(df3_wide, digits = 3, format.args = list(big.mark = ",", scientific = FALSE))
| 2,016 |
10,444,426 |
10,346,202 |
98,224 |
4,367,858 |
4,348,560 |
939,283 |
813 |
19,298 |
6,234 |
13,064 |
NA |
NA |
NA |
NA |
NA |
3,707,401 |
6,076,568 |
5,997,642 |
78,926 |
197 |
2,839 |
75,892 |
NA |
NA |
NA |
4,901,662 |
633 |
| 2,015 |
10,370,172 |
10,272,942 |
97,230 |
4,433,389 |
4,415,549 |
937,145 |
838 |
17,840 |
5,656 |
12,184 |
NA |
NA |
NA |
NA |
NA |
3,770,762 |
5,936,783 |
5,857,393 |
79,390 |
258 |
2,476 |
76,656 |
NA |
NA |
NA |
4,813,905 |
653 |
| 2,014 |
10,267,614 |
10,171,350 |
96,264 |
4,495,106 |
4,478,620 |
932,121 |
945 |
16,486 |
5,035 |
11,451 |
NA |
NA |
NA |
NA |
NA |
3,818,148 |
5,772,508 |
5,692,730 |
79,778 |
218 |
2,564 |
76,996 |
NA |
NA |
NA |
4,685,872 |
657 |
| 2,013 |
10,145,363 |
10,049,996 |
95,367 |
4,561,504 |
4,546,050 |
928,584 |
1,056 |
15,454 |
4,729 |
10,725 |
NA |
NA |
NA |
NA |
NA |
3,896,532 |
5,583,859 |
5,503,946 |
79,913 |
223 |
2,617 |
77,073 |
NA |
NA |
NA |
4,556,467 |
677 |
| 2,012 |
9,977,967 |
9,883,694 |
94,273 |
4,614,306 |
4,599,727 |
917,488 |
1,297 |
14,579 |
4,413 |
10,166 |
NA |
NA |
NA |
NA |
NA |
3,939,700 |
5,363,661 |
5,283,967 |
79,694 |
252 |
2,812 |
76,617 |
NA |
NA |
NA |
4,354,676 |
679 |
| 2,011 |
9,834,031 |
9,740,311 |
93,720 |
4,668,961 |
4,655,215 |
907,486 |
NA |
13,746 |
4,308 |
9,438 |
NA |
NA |
NA |
NA |
NA |
4,007,419 |
5,165,070 |
5,085,096 |
79,974 |
236 |
2,945 |
76,793 |
NA |
NA |
NA |
4,195,486 |
691 |
| 2,010 |
9,693,855 |
9,600,185 |
93,670 |
4,720,274 |
4,707,348 |
890,718 |
NA |
NA |
NA |
NA |
12,926 |
4,172 |
3,892 |
48 |
60 |
4,068,269 |
4,973,581 |
4,892,837 |
80,744 |
NA |
3,898 |
NA |
15,532 |
379 |
476 |
4,060,925 |
694 |
| 2,009 |
9,579,441 |
9,488,013 |
91,428 |
4,775,204 |
4,762,961 |
881,294 |
NA |
NA |
NA |
NA |
12,243 |
4,027 |
3,272 |
28 |
36 |
4,127,031 |
4,804,237 |
4,725,052 |
79,185 |
NA |
4,148 |
NA |
13,665 |
441 |
570 |
3,931,565 |
706 |
| 2,008 |
9,494,334 |
9,401,968 |
92,366 |
4,828,192 |
4,816,570 |
872,402 |
NA |
NA |
NA |
NA |
11,622 |
3,976 |
3,108 |
56 |
54 |
4,184,898 |
4,666,142 |
4,585,398 |
80,744 |
NA |
3,842 |
NA |
12,216 |
404 |
667 |
3,824,465 |
727 |
| 2,007 |
9,432,809 |
9,343,691 |
89,118 |
4,888,449 |
4,877,364 |
853,238 |
NA |
NA |
NA |
NA |
11,085 |
3,955 |
3,071 |
43 |
75 |
4,242,450 |
4,544,360 |
4,466,327 |
78,033 |
NA |
5,244 |
NA |
12,118 |
409 |
506 |
3,719,601 |
770 |
| 2,006 |
9,322,431 |
9,234,138 |
88,293 |
4,942,200 |
4,931,853 |
812,508 |
NA |
NA |
NA |
NA |
10,347 |
NA |
NA |
NA |
NA |
4,294,622 |
4,380,231 |
4,302,285 |
77,946 |
NA |
NA |
NA |
NA |
NA |
NA |
3,603,866 |
799 |
| 2,005 |
9,188,153 |
9,101,310 |
86,843 |
4,997,797 |
4,988,029 |
804,583 |
NA |
NA |
NA |
NA |
9,768 |
NA |
NA |
NA |
NA |
4,349,898 |
4,190,356 |
4,113,281 |
77,075 |
NA |
NA |
NA |
NA |
NA |
NA |
3,443,602 |
840 |
| 2,004 |
9,145,856 |
9,059,342 |
86,514 |
5,054,943 |
5,045,472 |
786,357 |
NA |
NA |
NA |
NA |
9,471 |
NA |
NA |
NA |
NA |
4,397,013 |
4,090,913 |
4,013,870 |
77,043 |
NA |
NA |
NA |
NA |
NA |
NA |
3,349,944 |
860 |
| 2,003 |
9,100,072 |
9,013,949 |
86,123 |
5,107,942 |
5,098,862 |
787,965 |
NA |
NA |
NA |
NA |
9,080 |
NA |
NA |
NA |
NA |
4,444,800 |
3,992,130 |
3,915,087 |
77,043 |
NA |
NA |
NA |
NA |
NA |
NA |
3,270,872 |
891 |
| 2,002 |
9,071,894 |
8,986,018 |
85,876 |
5,158,762 |
5,149,940 |
783,806 |
NA |
NA |
NA |
NA |
8,822 |
NA |
NA |
NA |
NA |
4,495,922 |
3,913,132 |
3,836,078 |
77,054 |
NA |
NA |
NA |
NA |
NA |
NA |
3,193,309 |
966 |
| 2,001 |
9,082,535 |
8,997,213 |
85,322 |
5,211,211 |
5,202,171 |
769,748 |
NA |
NA |
NA |
NA |
9,040 |
NA |
NA |
NA |
NA |
4,540,713 |
3,871,324 |
3,795,042 |
76,282 |
NA |
NA |
NA |
NA |
NA |
NA |
3,168,465 |
1,082 |
| 2,000 |
9,108,596 |
9,024,008 |
84,588 |
5,249,499 |
5,240,785 |
746,719 |
NA |
NA |
NA |
NA |
8,714 |
NA |
NA |
NA |
NA |
4,573,809 |
3,859,097 |
3,783,223 |
75,874 |
NA |
NA |
NA |
NA |
NA |
NA |
3,163,107 |
1,274 |
| 1,999 |
9,125,267 |
9,041,646 |
83,621 |
5,296,252 |
5,287,799 |
739,550 |
NA |
NA |
NA |
NA |
8,453 |
NA |
NA |
NA |
NA |
4,615,721 |
3,829,015 |
3,753,847 |
75,168 |
NA |
NA |
NA |
NA |
NA |
NA |
3,141,118 |
1,446 |
| 1,998 |
9,128,476 |
9,044,906 |
83,570 |
5,344,203 |
5,335,636 |
734,003 |
NA |
NA |
NA |
NA |
8,567 |
NA |
NA |
NA |
NA |
4,651,702 |
3,784,273 |
3,709,270 |
75,003 |
NA |
NA |
NA |
NA |
NA |
NA |
3,101,037 |
1,620 |
予想どおりのデータです。 ちなみに,年度のコンマは不要ですが,消し方が分からないため,表示されてしまいます。
もっともっと作図
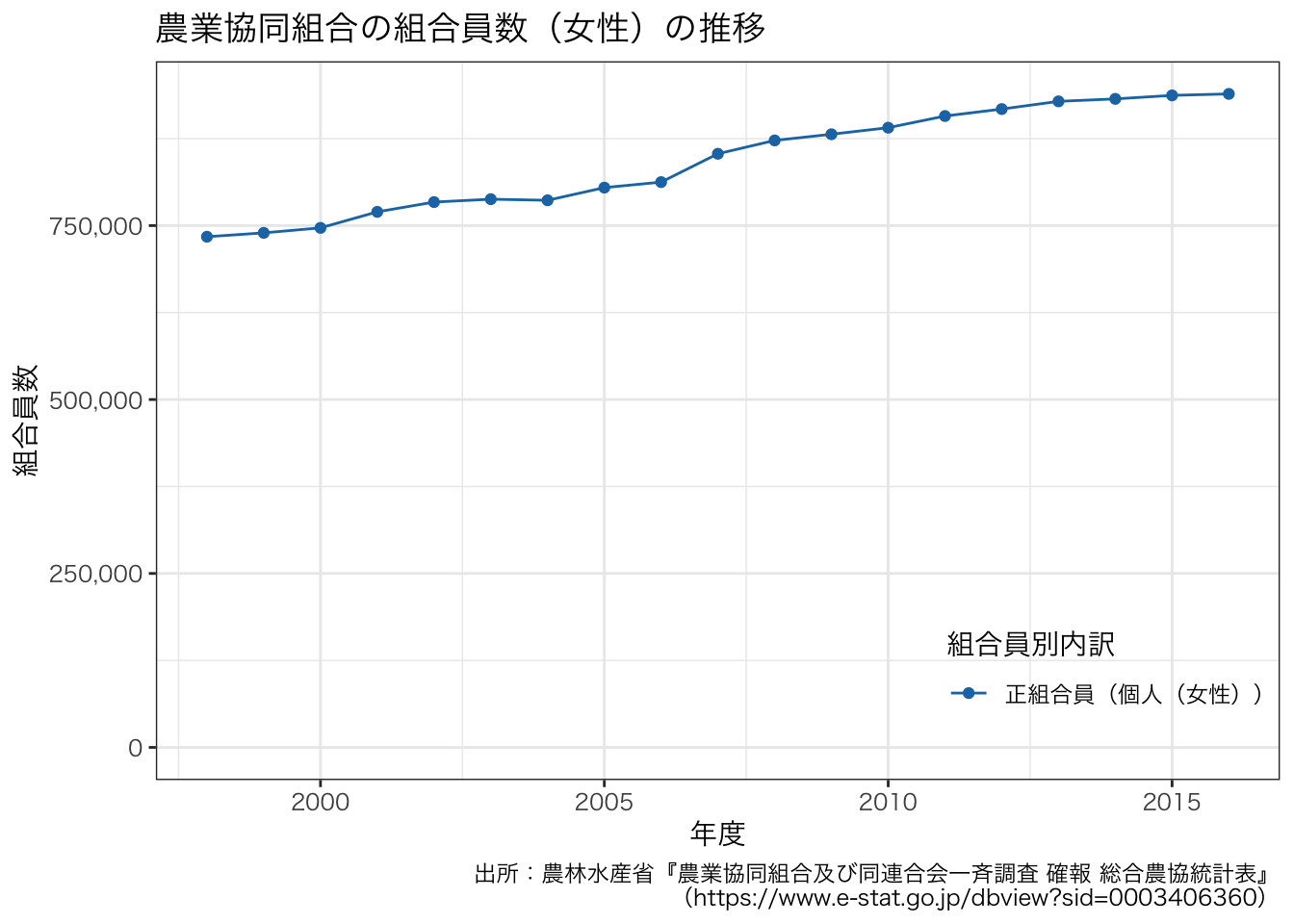
次に,授業では女性の組合員が増えていることを説明しました。 このことを実際のデータで確認してみましょう。
df_JAmembers <- df3[grep("^正組合員(個人(女性))$", df3$組合員別内訳), ]
df_JAmembers$組合員別内訳 <- droplevels(df_JAmembers$組合員別内訳)
g <- ggplot(data = df_JAmembers, aes(x = 年度, y = value, group = 組合員別内訳, colour = 組合員別内訳)) +
geom_line() +
geom_point() +
scale_y_continuous(limits = c(0, NA), labels = scales::comma, name = "組合員数") +
ggtitle("農業協同組合の組合員数(女性)の推移") +
labs(caption = "出所:農林水産省『農業協同組合及び同連合会一斉調査 確報 総合農協統計表』\n(https://www.e-stat.go.jp/dbview?sid=0003406360)") +
theme_bw() +
theme(legend.position = c(.85, .15),
legend.background = element_rect(fill = "transparent")) +
scale_color_d3()
g + theme(text = element_text(family = "HiraKakuProN-W3"))
ggsave(file = "ja_members_female.pdf", plot = g, path = outdir, width = 8, height = 4)
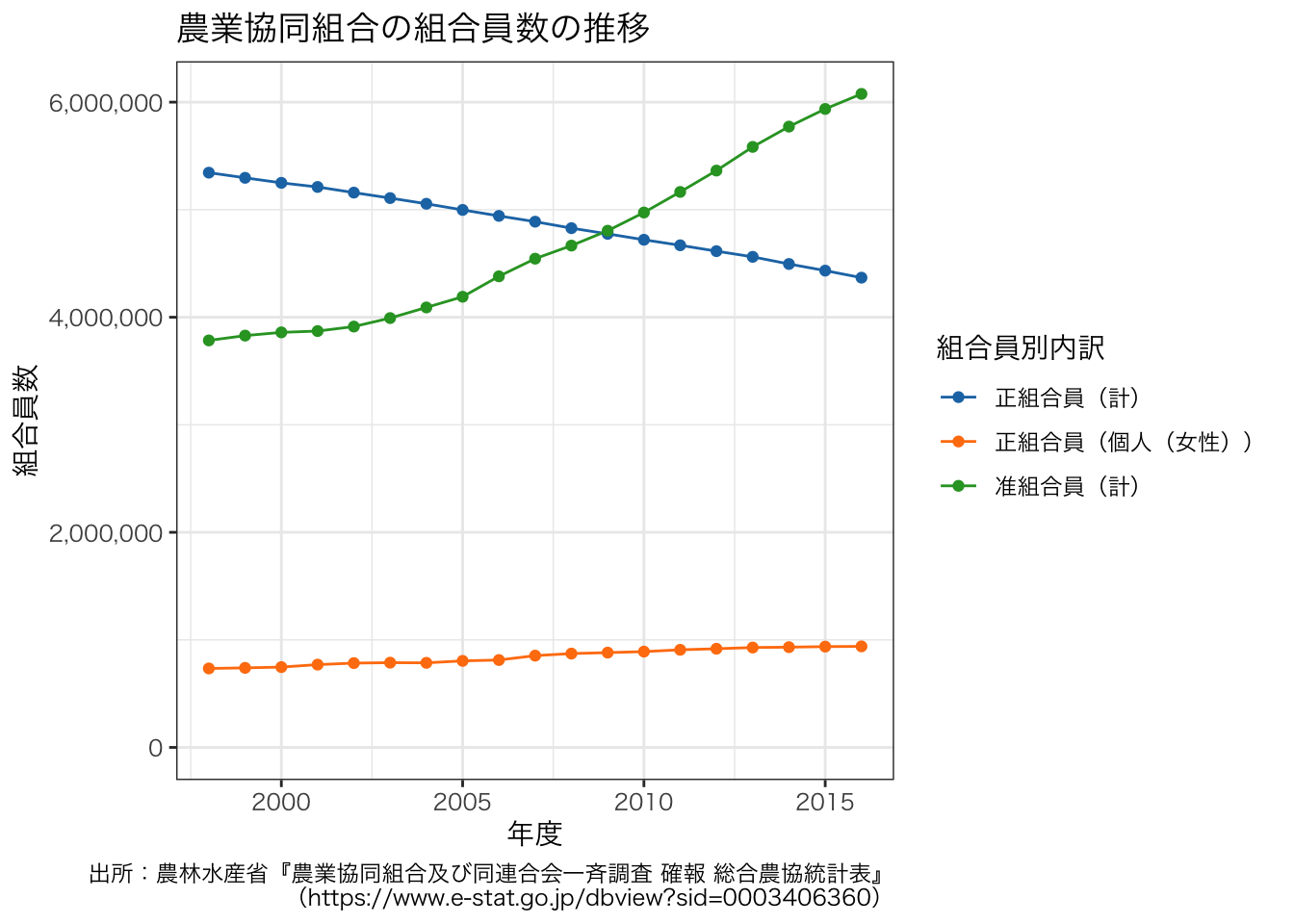
確かに女性の組合員は増加していることが分かります。 ただし,これだと組合員全体に占める女性の比率が分からないので,上述のグラフと重ねたグラフを描いてみます。
df_JAmembers <- df3[grep("^正組合員(個人(女性))$|^正組合員(計)$|^准組合員(計)$", df3$組合員別内訳), ]
df_JAmembers$組合員別内訳 <- droplevels(df_JAmembers$組合員別内訳)
g <- ggplot(data = df_JAmembers, aes(x = 年度, y = value, group = 組合員別内訳, colour = 組合員別内訳)) +
geom_line() +
geom_point() +
scale_y_continuous(limits = c(0, NA), labels = scales::comma, name = "組合員数") +
ggtitle("農業協同組合の組合員数の推移") +
labs(caption = "出所:農林水産省『農業協同組合及び同連合会一斉調査 確報 総合農協統計表』\n(https://www.e-stat.go.jp/dbview?sid=0003406360)") +
theme_bw() +
scale_color_d3()
g + theme(text = element_text(family = "HiraKakuProN-W3"))
ggsave(file = "ja_members_female_with_all.pdf", plot = g, path = outdir, width = 8, height = 4)
正組合員全体が減少している中で,女性が増加していることが1つのグラフでわかります。
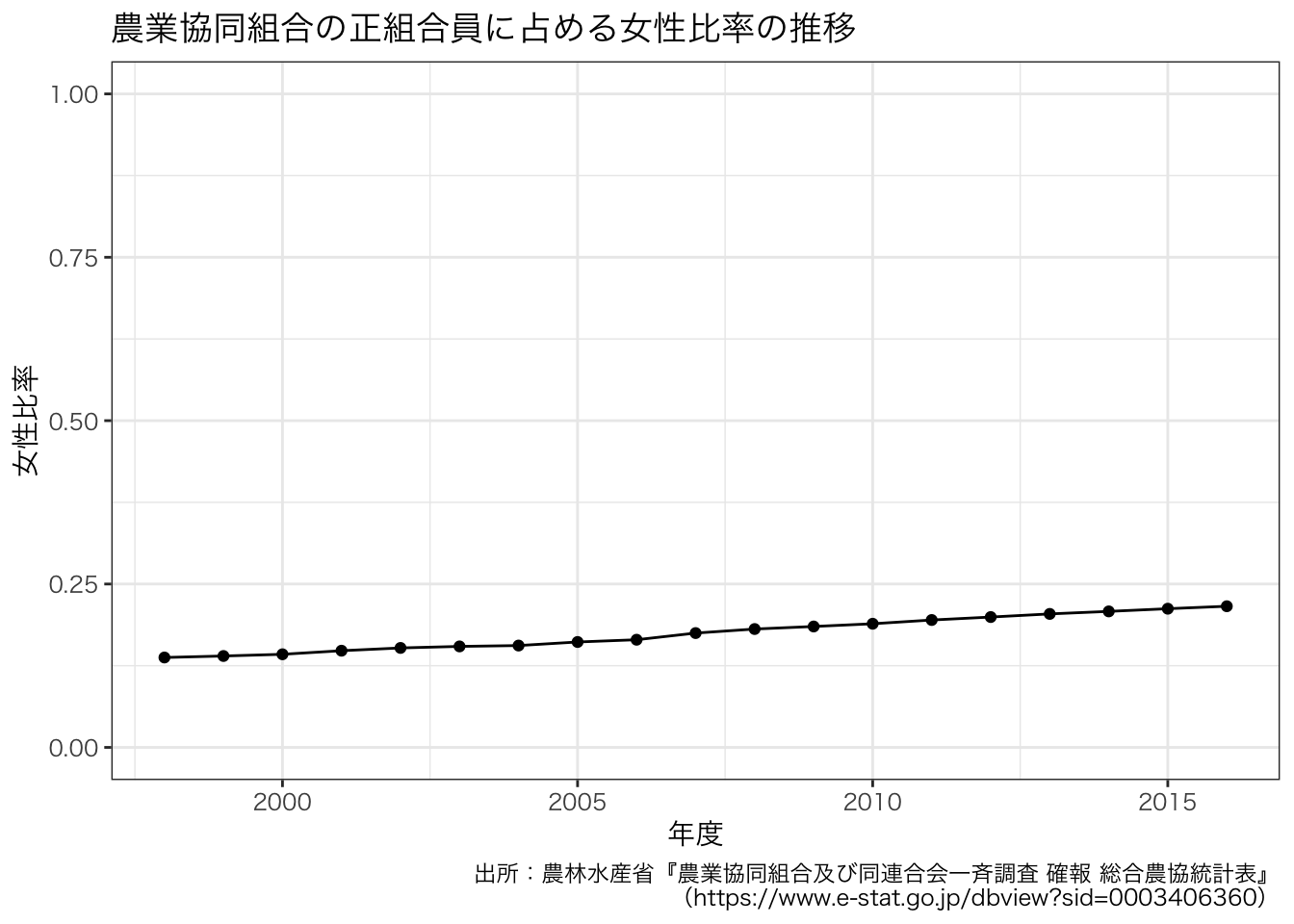
女性の増加に焦点を当てたければ,女性比率を計算するとよいかもしれません。 ここで,法人と団体は除いて計算することに気をつけましょう。
df_JAmembers <- df3[grep("^正組合員(個人(女性))$|^正組合員(個人)$", df3$組合員別内訳), ]
df_JAmembers <- df_JAmembers |>
tidyr::pivot_wider(id_cols = 年度, names_from = 組合員別内訳, values_from = value)
df_JAmembers$女性比率 <- df_JAmembers$`正組合員(個人(女性))` / df_JAmembers$`正組合員(個人)`
g <- ggplot(data = df_JAmembers, aes(x = 年度, y = 女性比率)) +
geom_line() +
geom_point() +
scale_y_continuous(limits = c(0, 1), name = "女性比率") +
ggtitle("農業協同組合の正組合員に占める女性比率の推移") +
labs(caption = "出所:農林水産省『農業協同組合及び同連合会一斉調査 確報 総合農協統計表』\n(https://www.e-stat.go.jp/dbview?sid=0003406360)") +
theme_bw() +
theme(legend.position = "bottom") +
scale_color_d3()
g + theme(text = element_text(family = "HiraKakuProN-W3"))
ggsave(file = "ja_members_female_ratio.pdf", plot = g, path = outdir, width = 8, height = 4)
凡例がなく,線と点の色が黒くなりました。 ここで描画に用いているデータフレームはワイドです。 ggplot2 で凡例を付け,色分けするためには,group を使わなければならず,そのためにはデータをワイドではなくロングにする必要があります。 ロングにしたときの1つの列を group と colour に書くとよいです。
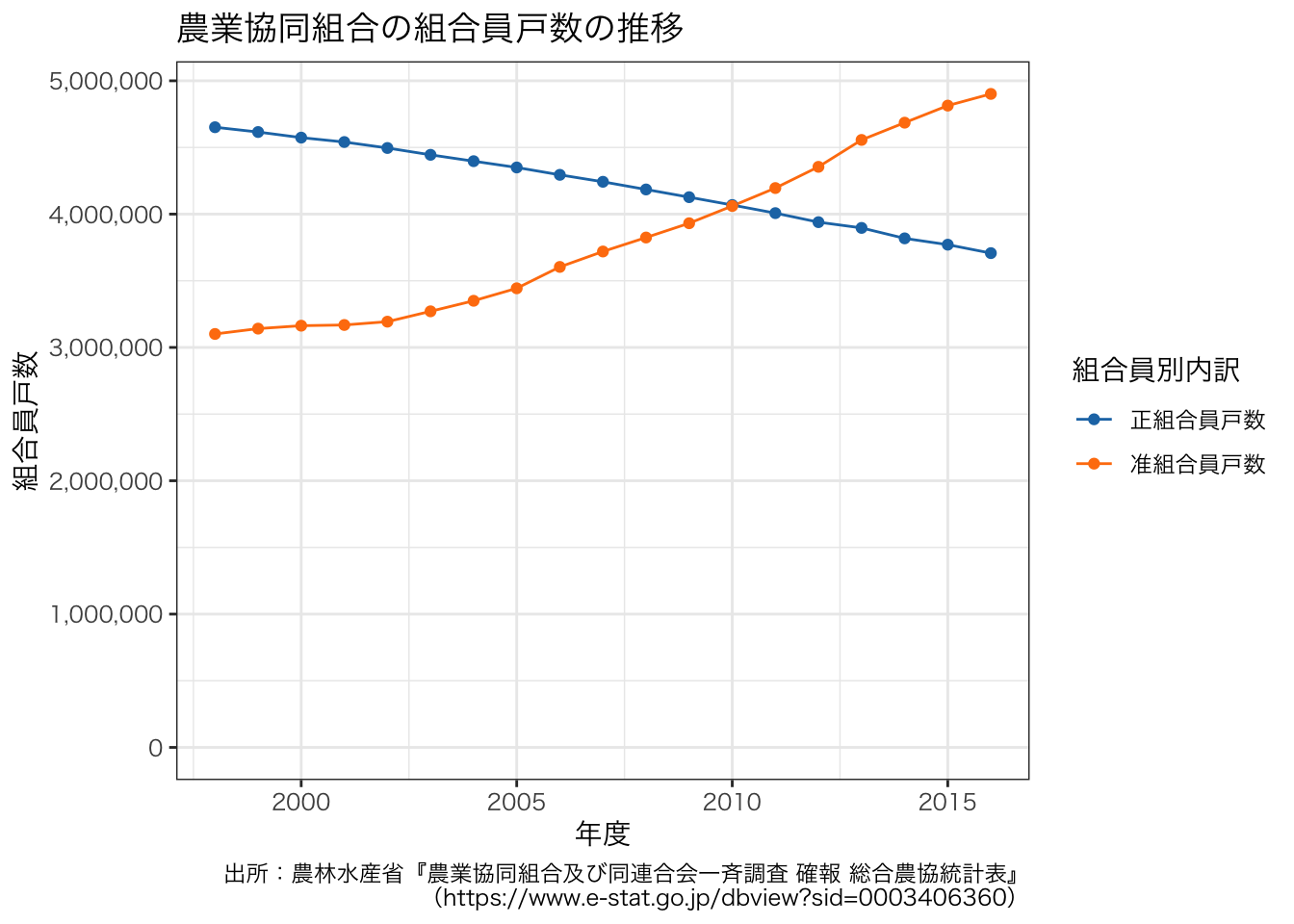
組合員戸数の推移はどうでしょうか。
df_JAmembers <- df3[grep("^正組合員戸数$|^准組合員戸数$", df3$組合員別内訳), ]
df_JAmembers$組合員別内訳 <- droplevels(df_JAmembers$組合員別内訳)
g <- ggplot(data = df_JAmembers, aes(x = 年度, y = value, group = 組合員別内訳, colour = 組合員別内訳)) +
geom_line() +
geom_point() +
scale_y_continuous(limits = c(0, NA), labels = scales::comma, name = "組合員戸数") +
ggtitle("農業協同組合の組合員戸数の推移") +
labs(caption = "出所:農林水産省『農業協同組合及び同連合会一斉調査 確報 総合農協統計表』\n(https://www.e-stat.go.jp/dbview?sid=0003406360)") +
theme_bw() +
scale_color_d3()
g + theme(text = element_text(family = "HiraKakuProN-W3"))
ggsave(file = "ja_members_household.pdf", plot = g, path = outdir, width = 8, height = 4)
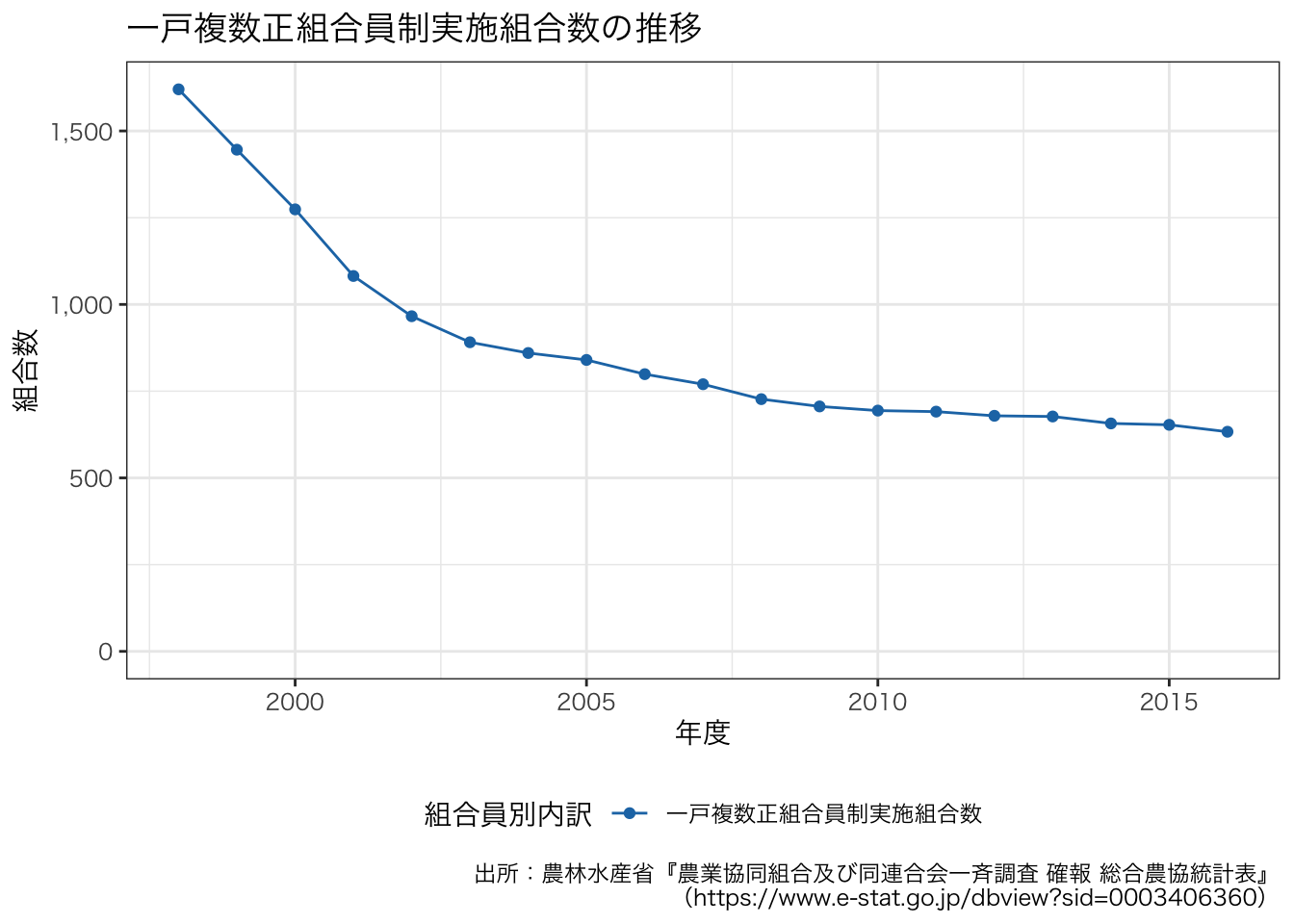
ここで扱っているのデータには,一戸複数正組合員制実施組合数の値も含まれています。 授業を踏まえると,この組合数は減少している可能性が考えられます。
df_JAmembers <- df3[grep("^一戸複数正組合員制実施組合数$", df3$組合員別内訳), ]
g <- ggplot(data = df_JAmembers, aes(x = 年度, y = value, group = 組合員別内訳, colour = 組合員別内訳)) +
geom_line() +
geom_point() +
scale_y_continuous(limits = c(0, NA), labels = scales::comma, name = "組合数") +
ggtitle("一戸複数正組合員制実施組合数の推移") +
labs(caption = "出所:農林水産省『農業協同組合及び同連合会一斉調査 確報 総合農協統計表』\n(https://www.e-stat.go.jp/dbview?sid=0003406360)") +
theme_bw() +
theme(legend.position = "bottom") +
scale_color_d3()
g + theme(text = element_text(family = "HiraKakuProN-W3"))
ggsave(file = "number_of_ja_multiple_members_per_household.pdf", plot = g, path = outdir, width = 8, height = 4)
実際にグラフを作成すると,一戸複数正組合員制実施組合数の現象が確認できます。 ただし,農業協同組合の数が減少しているため,この数値の解釈には注意が必要です。
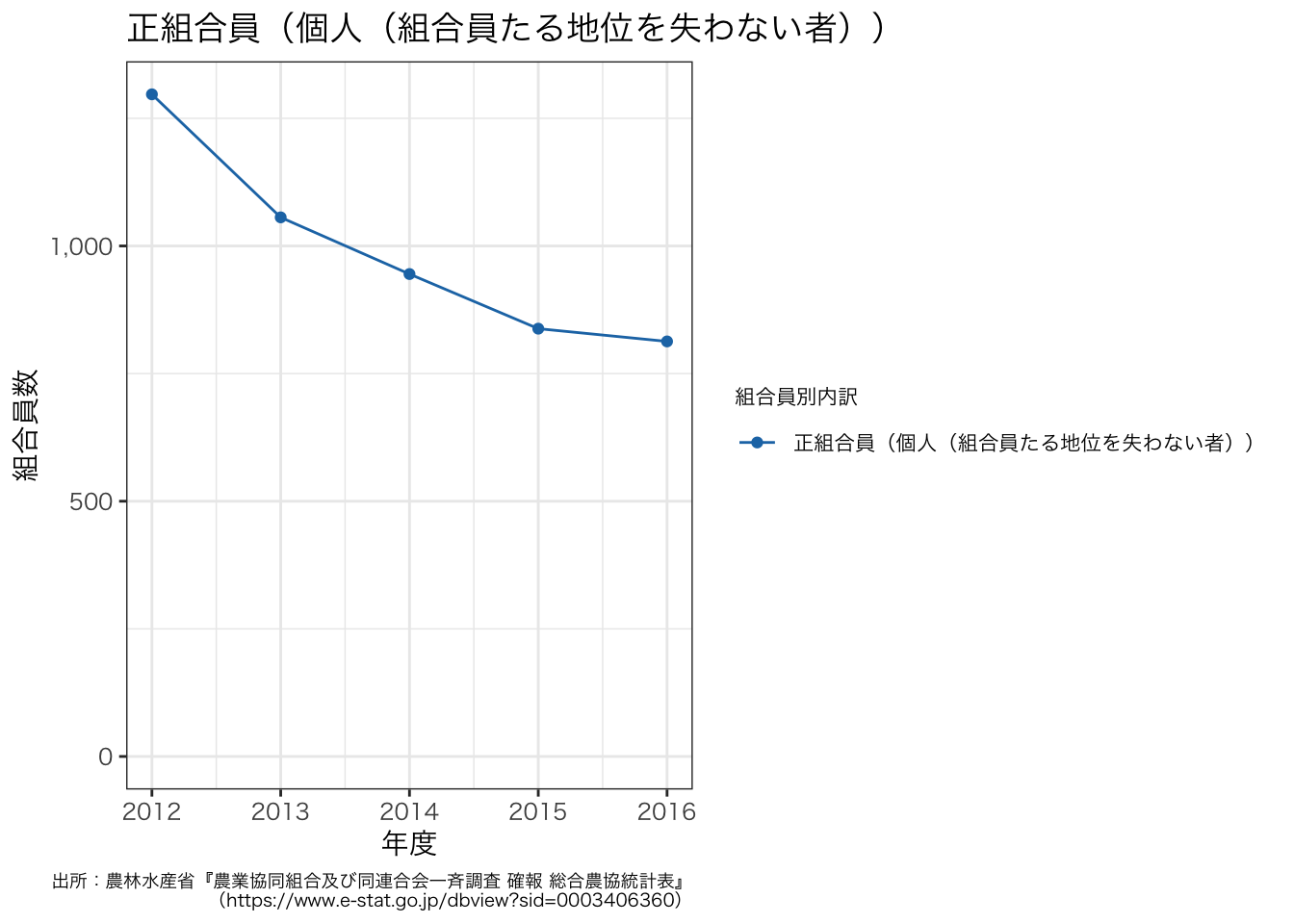
正組合員(個人(組合員たる地位を失わない者))は何でしょうか。 授業を踏まえると,これは土地持ち非農家の数を反映したものかもしれません。 定義については,統計データではなく,別の方法で調べます。 例えば,以下のような資料があります。
df_JAmembers <- df3[grep("^正組合員(個人(組合員たる地位を失わない者))$", df3$組合員別内訳), ]
g <- ggplot(data = df_JAmembers, aes(x = 年度, y = value, group = 組合員別内訳, colour = 組合員別内訳)) +
geom_line() +
geom_point() +
scale_y_continuous(limits = c(0, NA), labels = scales::comma, name = "組合員数") +
ggtitle("正組合員(個人(組合員たる地位を失わない者))") +
labs(caption = "出所:農林水産省『農業協同組合及び同連合会一斉調査 確報 総合農協統計表』\n(https://www.e-stat.go.jp/dbview?sid=0003406360)") +
theme_bw() +
theme(legend.title = element_text(size = 8),
legend.text = element_text(size = 8),
plot.caption = element_text(size = 7)) +
scale_color_d3()
g + theme(text = element_text(family = "HiraKakuProN-W3"))
ggsave(file = "ja_members_nonfarmer.pdf", plot = g, path = outdir, width = 8, height = 4)
都道府県別の作図
データフレーム df2 から df2$都道府県 == "全国" という条件で抽出したデータに基づいて全国のデータの図を描いたことから,df2$都道府県 != "全国" を抽出すれば都道府県のデータが得られると考えられるかもしれません。 確認してみます。
unique(df2$都道府県[df2$都道府県 != "全国"])
[1] "1組合当たり" "北海道" "東北_小計" "青森県"
[5] "岩手県" "宮城県" "秋田県" "山形県"
[9] "福島県" "関東_小計" "茨城県" "栃木県"
[13] "群馬県" "埼玉県" "千葉県" "東京都"
[17] "神奈川県" "山梨県" "長野県" "静岡県"
[21] "北陸_小計" "新潟県" "富山県" "石川県"
[25] "福井県" "東海_小計" "岐阜県" "愛知県"
[29] "三重県" "近畿_小計" "滋賀県" "京都府"
[33] "大阪府" "兵庫県" "奈良県" "和歌山県"
[37] "中国・四国_小計" "鳥取県" "島根県" "岡山県"
[41] "広島県" "山口県" "徳島県" "香川県"
[45] "愛媛県" "高知県" "九州_小計" "福岡県"
[49] "佐賀県" "長崎県" "熊本県" "大分県"
[53] "宮崎県" "鹿児島県" "沖縄県"
都道府県以外を1つずつ取り除いていく必要があります。 このとき,grepl() の正規表現の中に異なる条件を書くのが手っ取り早いです。
unique(df2$都道府県[!grepl("全国|小計|組合", df2$都道府県)])
[1] "北海道" "青森県" "岩手県" "宮城県" "秋田県" "山形県"
[7] "福島県" "茨城県" "栃木県" "群馬県" "埼玉県" "千葉県"
[13] "東京都" "神奈川県" "山梨県" "長野県" "静岡県" "新潟県"
[19] "富山県" "石川県" "福井県" "岐阜県" "愛知県" "三重県"
[25] "滋賀県" "京都府" "大阪府" "兵庫県" "奈良県" "和歌山県"
[31] "鳥取県" "島根県" "岡山県" "広島県" "山口県" "徳島県"
[37] "香川県" "愛媛県" "高知県" "福岡県" "佐賀県" "長崎県"
[43] "熊本県" "大分県" "宮崎県" "鹿児島県" "沖縄県"
grep() と grepl() の違いに注意しましょう。 都道府県のみ抽出されていることが確認できたら,実際にデータにこの抽出条件を用います。
df_pref <- df2[!grepl("全国|小計|組合", df2$都道府県), ]
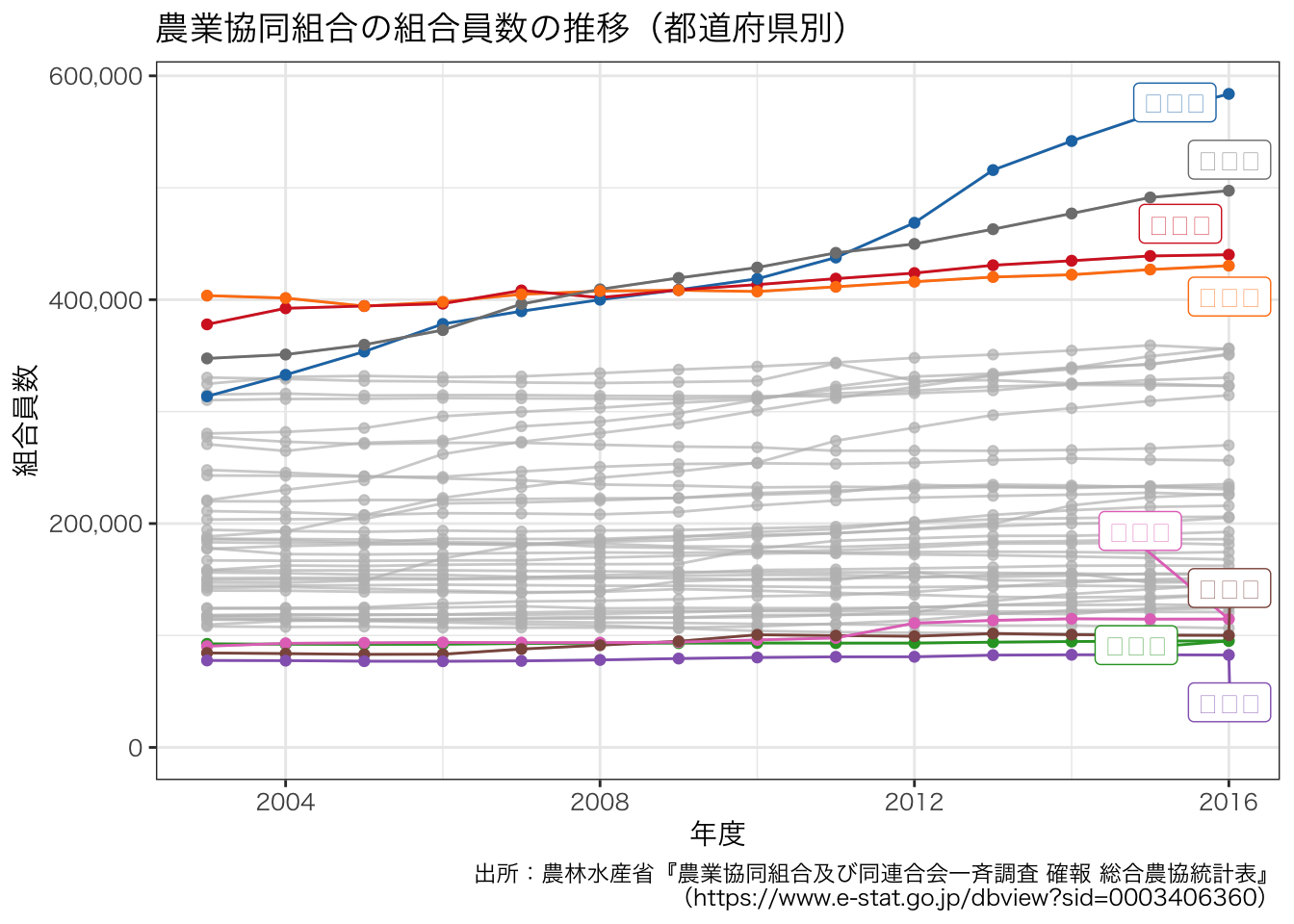
図の描き方は全国の場合とまったく同じです。 ただし,47本の折れ線グラフは判別しにくいため,特徴のあるものだけにラベルを表示するとよいでしょう。
library(gghighlight)
df_JAmembers <- df_pref |>
filter(grepl("^合計(計)$", 組合員別内訳))
df_JAmembers$組合員別内訳 <- droplevels(df_JAmembers$組合員別内訳)
g <- ggplot(data = df_JAmembers, aes(x = 年度, y = value, group = 都道府県, colour = 都道府県)) +
geom_line() +
geom_point() +
gghighlight(max(value) > 400000 | min(value) < 100000) +
# gghighlight(grepl("愛媛県", df_JAmembers$都道府県)) +
scale_y_continuous(limits = c(0, NA), labels = scales::comma, name = "組合員数") +
ggtitle("農業協同組合の組合員数の推移(都道府県別)") +
labs(caption = "出所:農林水産省『農業協同組合及び同連合会一斉調査 確報 総合農協統計表』\n(https://www.e-stat.go.jp/dbview?sid=0003406360)") +
theme_bw() +
scale_color_d3()
g + theme(text = element_text(family = "HiraKakuProN-W3"))
ggsave(file = "ja_members_pref.pdf", plot = g, path = outdir, width = 8, height = 4)
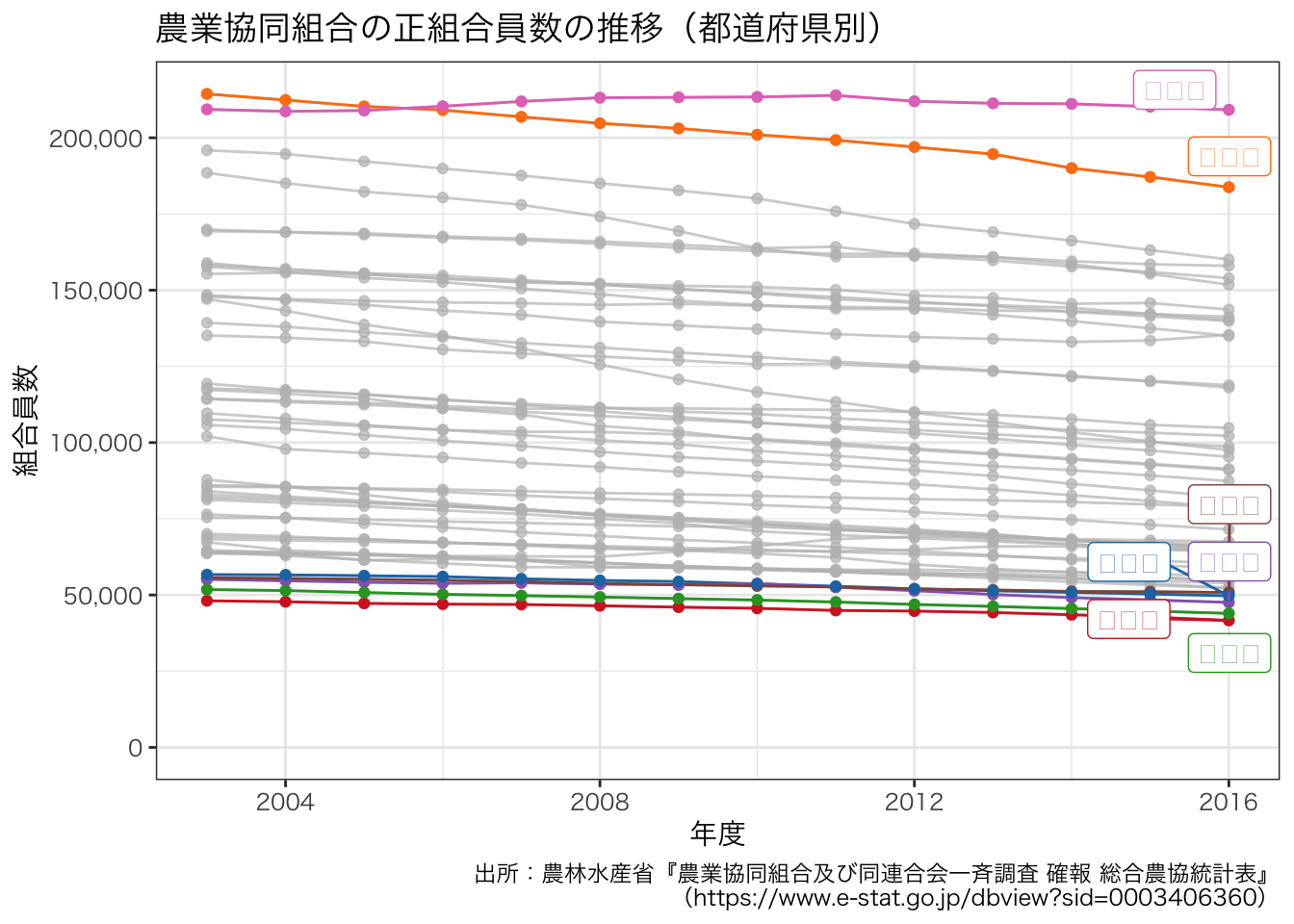
続いて,正組合員の折れ線グラフを描いてみます。
df_JAmembers <- df_pref |>
filter(組合員別内訳 == "正組合員(計)")
g <- ggplot(data = df_JAmembers, aes(x = 年度, y = value, group = 都道府県, colour = 都道府県)) +
geom_line() +
geom_point() +
gghighlight(max(value) > 200000 | min(value) < 52000) +
scale_y_continuous(limits = c(0, NA), labels = scales::comma, name = "組合員数") +
ggtitle("農業協同組合の正組合員数の推移(都道府県別)") +
labs(caption = "出所:農林水産省『農業協同組合及び同連合会一斉調査 確報 総合農協統計表』\n(https://www.e-stat.go.jp/dbview?sid=0003406360)") +
theme_bw() +
scale_color_d3()
g + theme(text = element_text(family = "HiraKakuProN-W3"))
ggsave(file = "ja_members_sei_pref.pdf", plot = g, path = outdir, width = 8, height = 4)
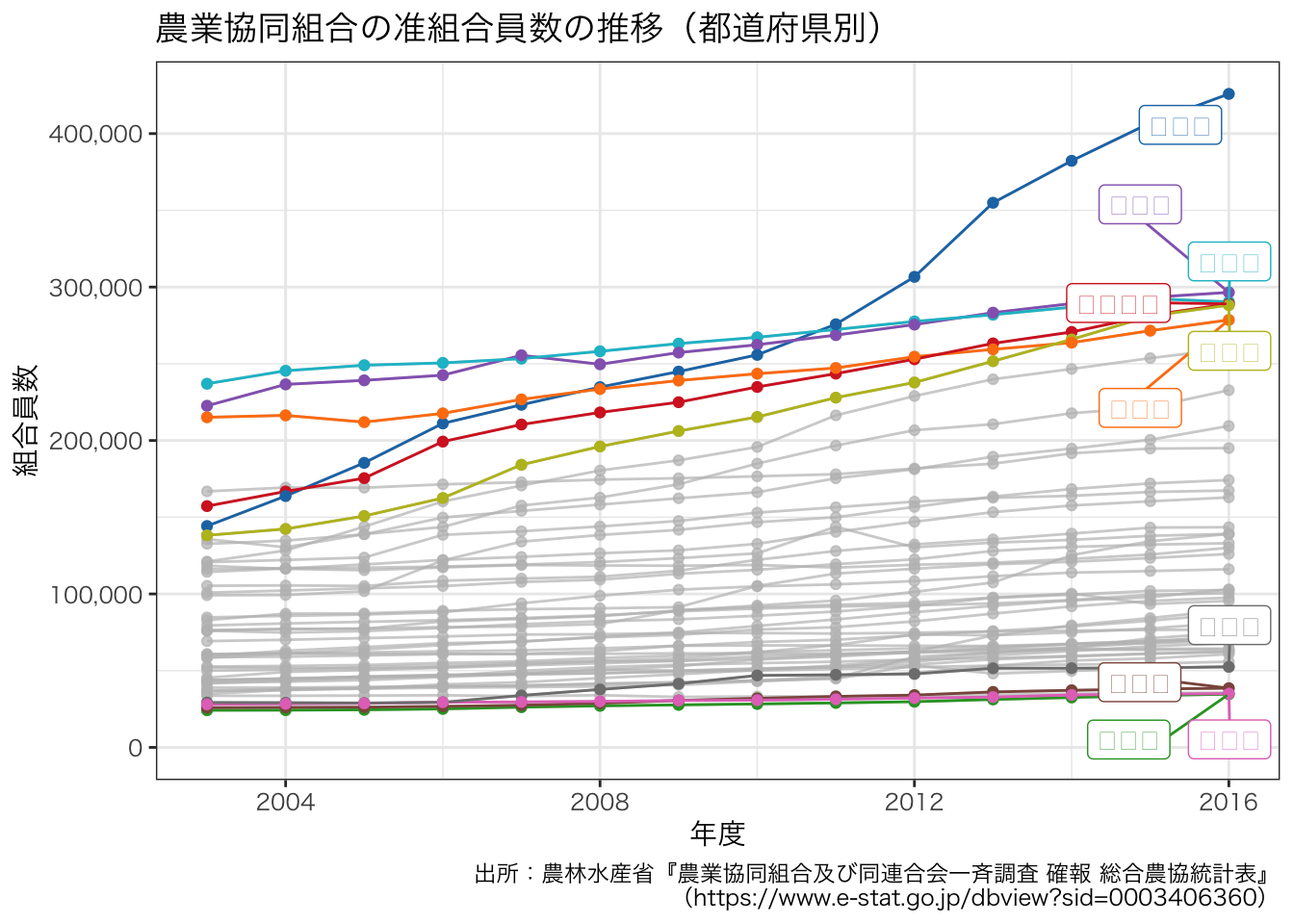
准組合員の折れ線グラフを描いてみます。
df_JAmembers <- df_pref |>
filter(組合員別内訳 == "准組合員(計)")
g <- ggplot(data = df_JAmembers, aes(x = 年度, y = value, group = 都道府県, colour = 都道府県)) +
geom_line() +
geom_point() +
gghighlight(max(value) > 260000 | min(value) < 30000) +
scale_y_continuous(limits = c(0, NA), labels = scales::comma, name = "組合員数") +
ggtitle("農業協同組合の准組合員数の推移(都道府県別)") +
labs(caption = "出所:農林水産省『農業協同組合及び同連合会一斉調査 確報 総合農協統計表』\n(https://www.e-stat.go.jp/dbview?sid=0003406360)") +
theme_bw() +
scale_color_d3()
g + theme(text = element_text(family = "HiraKakuProN-W3"))
ggsave(file = "ja_members_jun_pref.pdf", plot = g, path = outdir, width = 8, height = 4)
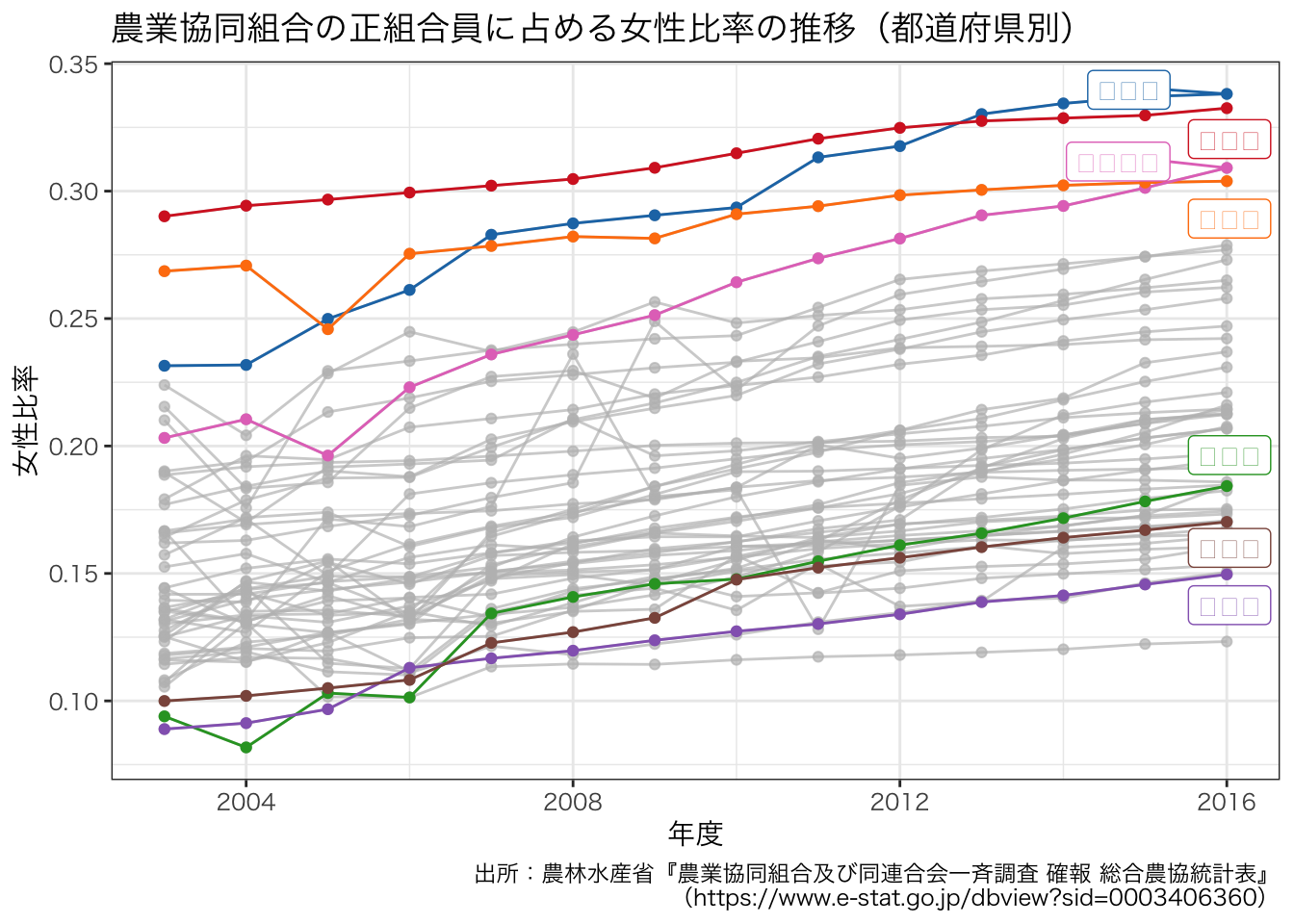
女性比率の高い都道府県と低い都道府県はどこでしょうか。
df_JAmembers <- df_pref[grep("^正組合員(個人(女性))$|^正組合員(個人)$", df_pref$組合員別内訳), ]
df_JAmembers <- df_JAmembers |>
tidyr::pivot_wider(id_cols = c(都道府県, 年度), names_from = 組合員別内訳, values_from = value)
df_JAmembers$女性比率 <- df_JAmembers$`正組合員(個人(女性))` / df_JAmembers$`正組合員(個人)`
g <- ggplot(data = df_JAmembers, aes(x = 年度, y = 女性比率, group = 都道府県, colour = 都道府県)) +
geom_line() +
geom_point() +
gghighlight(max(女性比率) > .3 | min(女性比率) < .1) +
ggtitle("農業協同組合の正組合員に占める女性比率の推移(都道府県別)") +
labs(caption = "出所:農林水産省『農業協同組合及び同連合会一斉調査 確報 総合農協統計表』\n(https://www.e-stat.go.jp/dbview?sid=0003406360)") +
theme_bw() +
theme(legend.position = "bottom") +
scale_color_d3()
g + theme(text = element_text(family = "HiraKakuProN-W3"))
ggsave(file = "ja_members_female_ratio_pref.pdf", plot = g, path = outdir, width = 8, height = 4)